Towards a Virtual Electronic Healthcare Record: The Patient Clinical Data Directory
Dimitrios G. Katehakis, Catherine E. Chronaki, et al.
Version 3.14, 12/18/98 10:38:28 AM
National and international healthcare networks are increasingly used to facilitate the sharing of health-related information and meet the healthcare needs of an increasingly mobile population. In this context, the vision of the Virtual Electronic HealthCare Record (EHCR) enables autonomous healthcare facilities to operate in a cooperative working environment and apply continuity of care.
This report describes the Patient Clinical Data Directory (PCDD), a middleware that provides clinical information on the distributed EHCR segments maintained by autonomous information systems in a regional health-telematics network such as HYGEIAnet, the regional health-telematics network of Crete. The PCDD maintains a distributed registry of feeder systems, patient key demographics, and references to clinical objects (medical encounters) inside patient EHCR segments. Feeder systems are the clinical information systems that qualify as PCDD information sources. They support diverse access methods ranging from human-mediated, to CORBA object references, and HTTP URLs. The PCDD middleware enables a Virtual EHCR service that provides an encounter-centered view of patient clinical data. The technological approach followed in the implementation of PCDD includes CORBA for inter-process communication, X.500/ LDAP for the directory infrastructure, and dedicated gateways (e.g. SQL/ ODBC-LDAP) for scheduled directory updates. The PCDD has been designed in the frame of the HYGEIAnet Reference Architecture (HRA), which provides a generic and evolving frame of reference for the reuse of services, components, and interfaces. A number of issues that affect the deployment of the PCDD at a regional scale, such as security and auditing, are addressed in the HRA context.
Recently, due to the greater mobility of the population as whole, national and international healthcare networks are increasingly used to facilitate the sharing of healthcare-related information among the various healthcare actors. This sharing of information resources is generally accepted as the key to substantial improvements in productivity and better quality of service [Teng95]. Hence, although each healthcare facility is autonomous and devoted to the delivery of a particular set of services, continuity of care requires that different healthcare facilities, offering complementary services or different levels of expertise, exchange relevant patient data, and operate in a cooperative working environment [Dilts91]. In this environment, diverse user groups require secure customizable access and sharing of information residing at geographically distributed autonomous information systems. Thus, a Healthcare Information Infrastructure (HII) that enables the coherent integration of heterogeneous components is necessary to reduce the inherent complexity of the related tasks. The core of the HII is middleware services that facilitate interoperability through open standards and public or protected interfaces.
As an example, consider the Virtual Electronic HealthCare Record (EHCR), one of the key user-oriented services enabled by an HII. Heterogeneous autonomous information systems designed to support specific data types, manage EHCR segments. Hence, comprehensive medical information about a patient is difficult to obtain efficiently, unless the distributed and heterogeneous EHCR segments are integrated into a Virtual EHCR and viewed on-line through a unified user interface and visualization environment [Forsland97] [Jagannathan95] [TelemedProject95] [CybTelemedOffice]. The seamless integration of distributed EHCR segments requires interoperability of heterogeneous autonomous information systems. As a result, standardization efforts for middleware that facilitate interoperability and enable the communication of information through standard messages are very active.
Health Level Seven (HL7) was founded in 1987 to develop standards for the electronic interchange of clinical, financial, and administrative information among independent healthcare-oriented computer systems [HL7Standards]. The ACR-NEMA Digital Imaging and Communications in Medicine (DICOM) standard [DICOM] has also been developed to meet the needs of manufacturers and users of medical imaging equipment for open interconnection of devices on standard networks. However the use of any single standard by all individual software components still could not satisfy the preferences of different customer groups. What was needed was to have increased site autonomy without loosing the benefit of using standards, and this is exactly the type of solution that has been used in electronic commerce systems [Asokan97] [Panurach96]. Here the standard used each time two components communicate has to be determined during their initial negotiation, and the only way to provide very high levels of autonomy to individual components, is to locate mediation services outside local systems. In this setting, general-purpose open integration standards like CORBA play a critical role, facilitating integration at different levels of abstraction. In addition, X.500/ LDAP directory services provide a robust universal infrastructure that enables the publishing of information on networked resources, in an attribute-value format. Through appropriate IDL interfaces, CORBA enables access to views of the information in a global directory, while LDAP provides tight integration and secure access to the full information model of the directory, under appropriate security constraints. This technological approach can support any consolidation efforts of today for offering regional healthcare resource services, and can function successfully as a global directory service in the future [isode].
This report describes the Patient Clinical Data Directory (PCDD), a middleware service that indices the EHCR segments of patients' health records and facilitates global access to patient clinical objects in feeder systems, i.e. geographically distributed, heterogeneous, autonomous clinical information systems. The PCDD maintains a distributed registry of feeder systems, patient key demographics, their EHCR segments, clinical meta-data, and references to clinical objects. The data model of the PCDD is based on the Subjective Objective Assessment Plan (SOAP) model that originated from the primary healthcare domain [Bainbridge96]. Access to detailed information on particular healthcare encounters is delivered on a case by case basis. Each feeder information system is responsible to provide an export schema and map it to the schema of the directory. With regard to updates, different update schedules can be applied at different sites. The core technologies of the PCDD are X.500/ LDAP directories, CORBA, data extraction gateways (such as ODBC-to-LDAP), and related Internet technologies.
The PCDD middleware fits naturally within the HYGEIAnet Reference Architecture (HRA), an evolving frame of reference for the reuse of services, components, and interfaces for the HII [Orphanoudakis98a] [Orphanoudakis98b]. The rest of the report is structured as follows. Section 2 (Internet Technologies) presents a review of the technologies that have affected the design of PCDD. The Virtual EHCR problem is introduced in Section 3 (Virtual EHCR Services). All the technical aspects of the PCDD architecture and use cases are covered in Section 4 (The Patient Clinical Data Directory). Following that, Section 5 (Current Status of the PCDD Federation) presents the current implementation state and planned extensions to the PCDD federation, discussing feeder systems that have been introduced to the federation (i.e. PHCCIS, PSCIS, and HECC) and feeder systems whose incorporation has been planned (i.e. PCDES, HyARC). Then, Section 6 (User-Oriented Services) describes user-oriented services that are enabled by the PCDD. Finally, PCDD is placed in the context of HYGEIAnet (Section 7 - HYGEIAnet Reference Architecture), addressing issues related to data presentation (Section 7.2 - Presentation Issues), as well as security and auditing (Section 7.3 - Security Issues). The report concludes with reference to related work (Section 8 – Related Work), as well as a discussion on deployment issues and planned extensions to the presented work (Section 9 - Discussion).
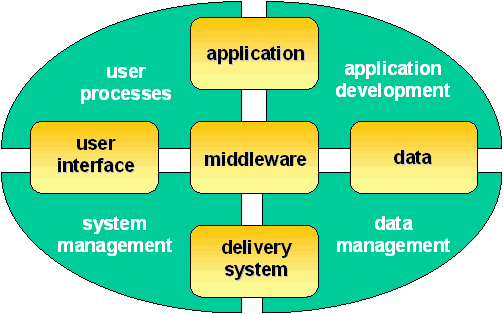
As shown in the Internet architecture of Figure 1 [Benda97], middleware connects the user interface (e.g. HTML), application, data (e.g. LDAP), and delivery system (e.g. JVM, RPC, Kerberos, CORBA time synchronizers). Inter-process communication is the heart of middleware, and three are the basic computing infrastructures that currently exist. OMG’s CORBA has been produced by a consortium of 700+ vendors and can support heterogeneous environments, Sun’s Java Base Platform supports network computers, and Microsoft’s COM targets the homogeneous Windows environment (personal computer).
Figure 1: Internet Architecture.
The COM run-time provides object-oriented services to clients and components and uses RPC and the security provider to generate standard network packets that conform to the DCOM wire-protocol standard [Microsoft96]. ActiveX components can be packaged in several different forms, but they are usually delivered as DLLs. As such, these components need to be installed, if only temporarily, into a user's system so that they can be executed. On the other hand, a component constructed according to the JavaBean recipe will execute on any system that provides a Java execution environment [Renshaw98]. In other words, JavaBeans are platform-independent. CORBA works through software engines that are called ORBs. An ORB delivers requests to objects and returns any responses to the clients making requests [Vinoski97]. An ORB can translate among different data formats and individual processor characteristics, making CORBA objects operating-system and programming-language independent.
No matter what is the technology of choice, the adoption of a component approach in server applications, saves a lot of time in maintenance and increases the potential for future improvements. Already, several ORB vendors, including Digital, HP, Iona, and SunSoft, bridge the gap between CORBA and DCOM by enabling the use of COM on the desktop and CORBA on the server, or by wrapping one within the other [Foody97]. The object infrastructures of CORBA and Java complement each other, since CORBA deals with network transparency, while Java deals with implementation transparency [Cashin97]. The learning curve for implementing CORBA is higher than for ActiveX or Java, but once that's been climbed, it seems to deliver industrial-strength results. In addition, CORBA supports features such as implementation inheritance that COM lacks.
Figure 2 depicts a typical approach for accessing a remote EHCR segment, through a web browser. A web server provides access to EHCR data, and the user access point is a typical web browser. There are different methods to implement web access through a Web Server. These include CGI, IDC, or ASP technologies, using ODBC or native database drivers for accessing local DBMSs. All these approaches work in a very similar way, as long as the clinical information system supports one of the points of access mentioned above, and the software developer team possesses the expertise for using the necessary tools required each time. In all cases, a web browser is the client (since it is available to the public and provides uniform means of access), and the clinical information system database is the source of information.
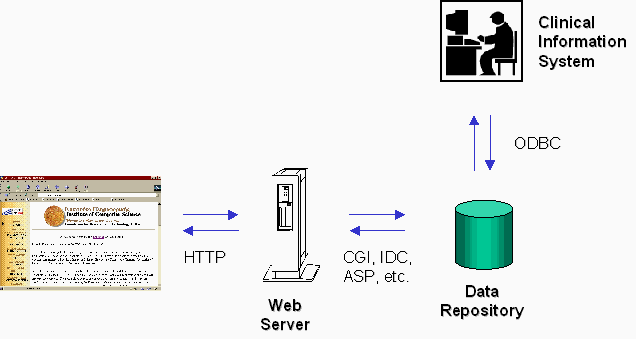
Figure 2: A Simplistic Approach to Data Access By Means Of the WWW.
According to [Kim96] the architecture of database gateways can be classified into two main categories; server-side extension and client-side extension. In the server-side extension, a database gateway is invoked through a CGI, the server API, or a proprietary server. In the client-side extension, a database gateway may be placed within external viewers, or a browser may be extended so that it can connect a database system directly. The use of CGI can be further divided into the case where a database gateway runs as a CGI executable itself (Figure 3) and the case of a CGI application server where CGI is just used to pass requests to separate database application servers. The CGI executable approach, shown in Figure 3, although simple and straightforward, carries several disadvantages. It consumes a relatively large amount of system resources since the HTTP server needs to spawn a CGI script at every request, and it does not take advantage of the DBMS’s optimization techniques. In addition, the CGI database gateways released by leading RDBMS vendors, are typically quick efforts to illustrate what is possible, and developers usually have to do a fair amount of programming to implement real solutions [Frank95].
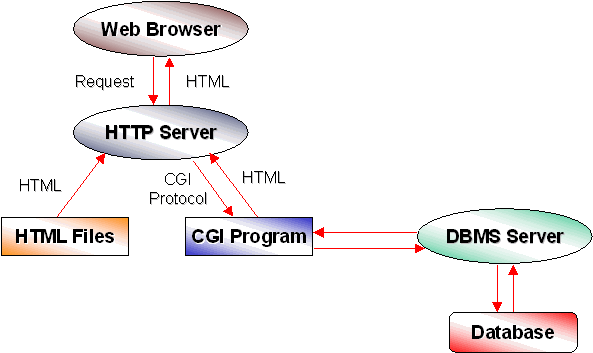
Figure 3: Use of CGI to Access DBMS Data.
The advantage of using a server API (like e.g. Microsoft’s ASP), is that applications are dynamically linked to the web server process reducing the cost of process management. At the same time the implementation is subject to a proprietary server API, with all the implications of a closed solution. External viewers (like in the Java applet case) are built by configuring existing database applications and the web, and hence they do not limit the database interface to web technology. On the other hand, they are not easy to update and maintain. Finally, any browser extension (this is the case of a web browser, with a script interpreter and any database access functions) overcomes the limitations of HTML, and has much possibility to cooperate with other software components, but there is still no standardization effort with regard to the client-side extension.
A more sophisticated approach includes an external viewer and an application server based on CORBA technology (Figure 4). In this approach the web browser downloads an HTML page that includes references to embedded Java applets. The web server retrieves each applet and downloads it to the browser in the form of bytecodes. The web browser loads the applet, which is first run through the Java run-time security gauntlet and then loaded into memory. The applet invokes CORBA server objects. The session between the Java applet and the CORBA server objects persist until either side decides to disconnect. Server objects can optionally generate the next HTML page for this client and inform the client what URL to download next [Orfali97] [Resnick96].
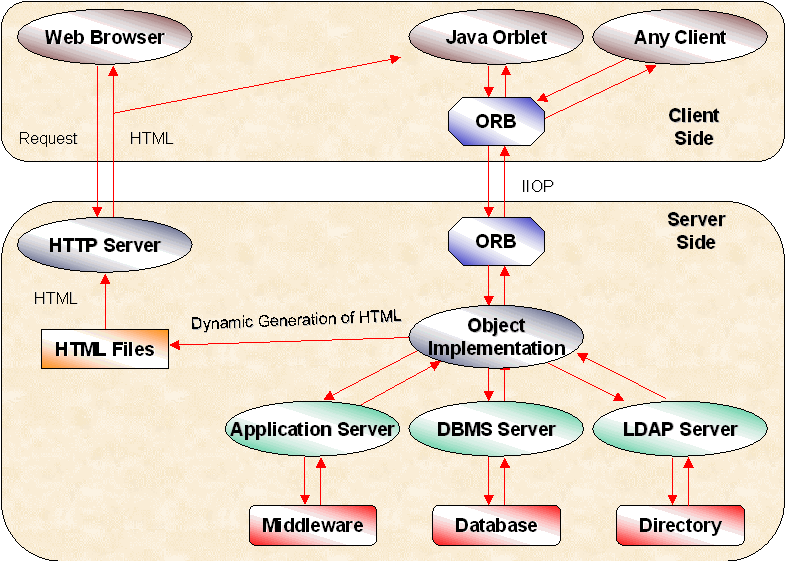
Figure 4: Access To Middleware Services By Means Of Java Orblets.
The CORBA approach offers a scalable server-to-server infrastructure, since pools of server business objects can communicate using a CORBA ORB. These objects can run on multiple servers to provide load balancing for incoming client requests [OrbixWeb97]. The ORB can dispatch the request to the first available object and add more objects as the demand increases. In contrast, a CGI application is a bottleneck because it must respond to thousands of incoming requests, and has no way to distribute the load across multiple processes or processors.
Relational databases are currently used extensively for storing enterprise data. A key strength of relational databases is their ability to make complex queries about the relationship between objects. Directories are specialized databases with a hierarchical information model, which are defined in terms of open, standardized, and vendor-neutral protocols, namely X.500 and LDAP. Key strengths of directory technology are its distributed provision and fast lookup based on name [Kille96]. On the other hand, Network Operating System (NOS) directories (e.g. Novell’s Directory Service) are "low level" directories used to support location of computer servers, printers and other Local Area Network (LAN) resources. Microsoft’s Active Directory, which is a new directory service from Microsoft (it will be part of the Windows 2000 Operating System), aims towards enhanced system integrity, in order to offer personalized user environments, simplified service and application configuration, security service integration, and improved bandwidth allocation [Microsoft98].
In essence, the directory is a distributed database capable of storing in a hierarchical data model, information about people and objects in various nodes or servers distributed across a network. It is these servers that provide the potentially global access to information, which is made possible by X.500 technology [ITU93a]. According to [Shuh97] both the X.500 directory and LDAP have been identified as key components in the development of meta-directories. X.500 provides the central directory, controls and facilitates access to data in proprietary directories, while LDAP controls the communication from directory users, and retrieves and populates the proprietary directories with the core information.
Current directory technologies use the Internet standards (i.e. TCP/ IP), conform to a global naming structure (i.e. DNS), provide public interfaces for directory access (e.g. LDAP), integrate and maintain synchronization with other transitional directories, and support security (i.e. X.509 and Kerberos). Since many users wish to access directory information via the Web, the WWW has an important relationship to the directory and is a key element to any directory solution.
Development teams around the world choose the set of tools they consider appropriate and concentrate their efforts on making the most of their use. Large companies involved in the manufacturing of medical equipment, management, and health-informatics, develop software that provides to a large extend, closed solutions. Furthermore, they claim that their own "complete" solution is better than all other. However, no single organization is able to make and to maintain the complete range of software it needs, let alone dominate the market. This situation has created islands of technology within or across healthcare facilities, making the quest towards achieving interoperability a major issue.
A horizontal integration model enabled by appropriate middleware presents a promising approach to interoperability problems. The adoption of such a model requires an integration architecture like CORBA paired with general and healthcare-related standards. The role of the integration architecture is to facilitate the seamless inter-working of general-purpose and healthcare-related middleware services. The resulting open and extensible framework conforms to standards and provides interoperability with other actors in the healthcare domain, realizing integrated media-rich, user-oriented services [Tsiknakis97].
There are a number of general-purpose and healthcare-related standardization efforts that need to be considered in different areas of a healthcare organization. Diagnostic imaging repositories store multi-dimensional image data (i.e. text, audio, video, etc.) and support DICOM interfaces for work-lists, data acquisition, and archiving [NEMA93]. Administrative information systems support HL7 interfaces for patient Admission-Transfer-Discharge (ATD) messages, orders of drugs, procedures, tests or their results, messages related to billing or financial information, and clinical observations focusing on measurements. Relevant general-purpose standards include well-documented IDL interfaces [Siegel96], SQL and ODBC for database connectivity [Creamer95], EDIFACT for financial transactions [EC96], SSL for secure data transfer [Freier96], XML for uniform presentation of healthcare objects in the browser environment [Conolly97], LDAP for directory access, and Z39.50 for information access queries [ANSI97].
Well-documented interfaces expressed in the Interface Definition Language (IDL) associated with the integration framework of CORBA, provide basic support for interoperability among computer systems. This is particularly important in large hospitals, where many kinds of different computers have been installed and cannot be changed. CORBAmed [CORBAmed] as the Healthcare Domain Task Force (DTF) of the Object Management Group (OMG) [OMG] defines standardized object-oriented interfaces that serve to promote interoperability between a variety of platforms, operating systems, languages and applications, in the healthcare domain. OMG does not create standards, instead, it creates the criteria for them by finding vendors who are ready to invest in CORBA. One year after issuing the RFP, the standard is ready, its interface specifications are adopted by OMG, and any of its 750+ members can find it on the web and download it. Due to the fast-track process it takes approximately 1.5 years for a standard to be produced, compared to a 7-8 year period required by other standardization organizations.
The primary mission of CORBAmed is to improve the quality of care, while reducing costs by means of CORBA technologies for interoperability. CORBAmed’s efforts concentrate on the standardization of IDL interfaces. Models and architectures adopted can be easily used by any alternative implementation (e.g. DCOM). The results of the CORBAmed efforts influence the design of interfaces developed worldwide.
There is a number of on-going activities within CORBAmed, which span to different areas of a healthcare organization.
COAS corresponds to an interface that is lower than LQS and handles the exchange of clinical data. LQS is placed at a higher layer and takes care of possible semantic inconsistencies in the medical terms. Consider the problem of addressing a query to multiple information systems. The query is composed of standard terms for clinical objects, taken from a medical dictionary, while the information systems use different terms for the same clinical objects. COAS provides a general interface to access clinical information systems and LQS provides a standard interface to create a mapping among these interfaces. Thus, LQS is used to translate the terms in the query to terms used by the information system and COAS is used to access the information system. LQS is used again to present the response of the information systems using terms in the "standard" dictionary. In addition, CORBAmed’s Person Identification Service (PIDS) [PIDS98] provides a set of interfaces that enables publishing person identification in different domains as well as correlation of these identifications based on identification traits (sequence of characteristics). PIDS serves both to identify and locate a person across systems, and has been adopted as a generic OMG interface standard.
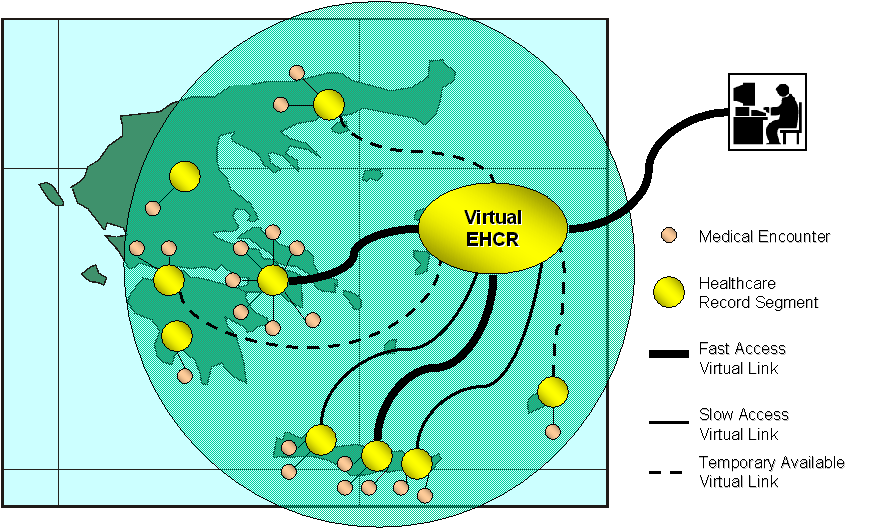
Figure 5: Access To the EHCR Segments of A Patient’s Health Record Involves Diverse Access Methods, and Highly Variable Access Times.
These considerations led to the design of the PCDD federation, which provides information integration at the enterprise-level and is enabled by a directory infrastructure that implements a distributed registry of EHCR segments. This approach realizes a federation of clinical information systems, is capable of supporting any consolidation efforts of today for Virtual EHCR services, and can function successfully as part of a global directory service in the future (see Figure 6). The hierarchical structure of the directory, although limited at first sight, provides a powerful way to index the geographically distributed EHCR segments and can facilitate the provision of a Virtual EHCR service (Section 6.1). The directory maintains a distributed registry for feeder systems and patients in the federation, as well as references to specific clinical objects in the EHCR segments of these patients. Since the directory stores access information for clinical objects in the EHCR segments, it may act as an access mediator. Thus, the treating physician, assuming authorization is granted, may use one of the available access methods, to access relevant clinical objects in the feeder systems.
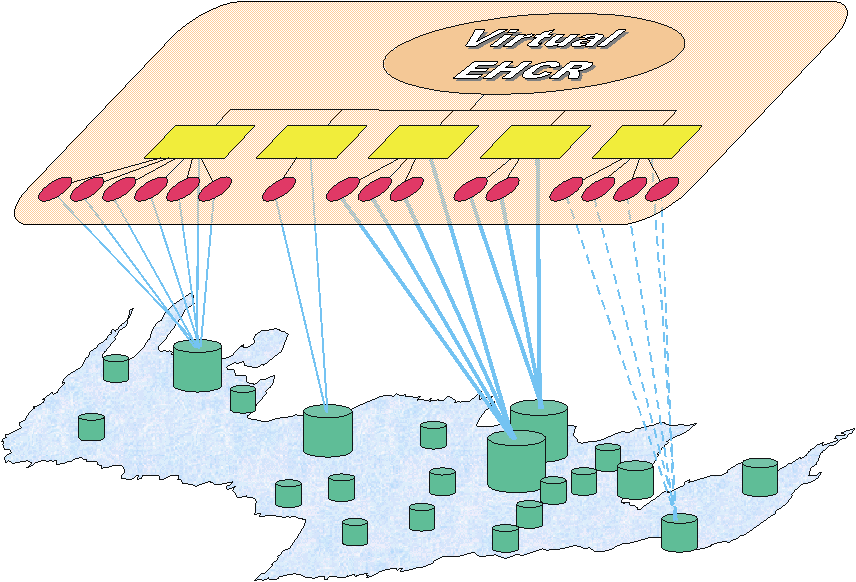
Figure 6: The Virtual EHCR Mediates Access To The Distributed Segments Of A Patient’s Healthcare Record. This Mediation Is Enabled By A Directory Infrastructure.
Figure 7 uses the Unified Modeling Language (UML) to express a number of key Virtual EHCR scenarios. These scenarios show common activities that involve remote access, visualization, and manipulation of EHCR segments. The most common scenario involves a treating physician who needs to browse the EHCR segments of a particular patient and access clinical data in feeder systems, i.e. clinical information systems that are part of the federation. A second scenario involves a treating physician who has requested a diagnostic examination in a central healthcare facility and monitors the status and results (objective data) of the examination during subsequent visits of the patient. A third use case applies to a treating physician who has referred a patient to an expert in another facility and wishes to access follow-up clinical objects relevant to the referral.
In UML, an actor is a human agent or application that interacts with a system, without being a part of the system [Fowler98]. Use cases represent the capabilities provided to an actor by the system. A use case is nothing more than a sequence of transactions producing measurable results of values to a particular actor [Quatrani98]. The three main actors that appear in the use case diagram of Figure 7 are the End User, the Clinical Information System, and the Directory. An additional actor is the Diagnostic Examination. End users may be administrative personnel, physicians, nurses, secretaries, and of course patients, with their own personal security access rights and privileges. Figure 7 shows two cooperating instances of the directory, namely the PCDD and the Healthcare Resource Map (HRM). The HRM describes the organizational structure, medical services, and personnel of the various healthcare facilities and provides multiple views of the healthcare resources in the region.
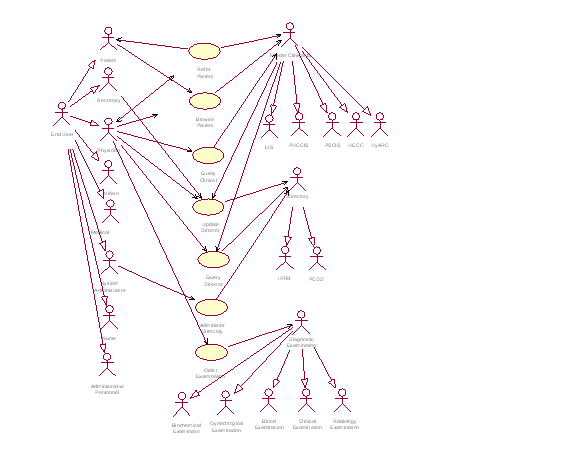
Figure 7: UML Use Case Diagram of Common Activities That Involve Remote Access, Visualization, And Update of EHCR Segments.
The PCDD supports currently all use cases depicted in Figure 7 (i.e. Update, Query, and Administer). Note however, that the actual acts of patient referral and diagnostic report ordering are beyond the current scope of the PCDD. On the other hand, a physician that has requested a referral may follow related activities through the directory and may check to see if a diagnostic report has been generated. Next Section presents the PCDD in detail, illustrating the conceptual model, architecture, interfaces, and core use case scenarios.
The main objective of the Patient Clinical Data Directory (PCDD) middleware is to provide basic support for Virtual EHCR services in a consistent, reusable, and extensible way. The PCDD indexes patient and feeder system identification, as well as information about clinical objects in a patient’s EHCR segments. This information is accessible to authorized users and applications through stable IDL interfaces. The central component of PCDD is an X.500/ LDAP directory, which maintains a registry of feeder systems, patient key demographics, their EHCR segments, clinical meta-data, and references to clinical objects.
Information about clinical objects in the directory refers to clinical patient data that are produced during the communication about the patient, between two or more individuals, at least one of whom is a member of the healthcare team currently involved [Bainbridge96]. This communication is called encounter. The most common type of encounter is a visit to a medical office, clinic, or primary healthcare center. Medical encounter entries in the directory follow the Subjective Objective Assessment Plan (SOAP) model of Figure 8. The SOAP model is an approach for recording clinical data generated during the contact of a patient with a healthcare provider. Subjective refers to the reason of the contact (i.e. the context of the encounter). Objective applies to medical examinations requested or reviewed during the contact e.g. blood examination, biochemical examination, computerized radiography (CR), etc. Assessment refers to the clinical diagnosis and associated reports. Plan refers to the clinical actions that must be taken, i.e. the treatment plan (drugs, surgery, etc.).

Figure 8: Medical Encounter Entries in the Directory Follow the SOAP Model.
The PCDD also provides the information required for accessing clinical multimedia information directly from its source (i.e. PCDD feeder systems). Feeder systems may support a wide variety of access methods ranging from human-mediated, to CORBA object references, and HTTP URLs. Furthermore, access to these systems is subject to site-specific authorization policies and is available through the regional HII. The PCDD does not deal with the semantic mapping problem directly. It is the responsibility of a feeder system to map an export schema of its information model to the directory information model. The underlying assumption is that a human who understands the semantics of the directory model both and the export schema of the feeder provides this mapping system [Pitoura95] [Synapses97a] [Synapses97b]. A minimal export schema of a feeder system should express the existence of a patient’s EHCR segment by providing patient identification attributes.
Each patient in PCDD has multiple HealthcareRecordSegments, which correspond to the segments of the patient’s EHCR. Each HealthcareRecordSegment resides in a feeder system (SystemInstallation) and consists of a set of MedicalEncounters belonging to the specific patient. The directory supports a number of feeder SystemTypes, each of which has been installed in a number of healthcare organizations (feeder SystemInstallations). A list of possible abbreviations used for identifying healthcare organizational units in HYGEIAnet, is listed on Table 1. All feeder systems need not be identical. Location and access methods may differ too. The minimum information that a feeder system should provide is the fact that a given patient has an EHCR segment in the particular information system.

Table 1: Abbreviations of Organizational Units in Healthcare Facilities.
The structure of the directory information tree for the PCDD appears in Figure 9. Each entry is identified among entries of the same object class by its Relative Distinguishing Name (RDN). The RDN for patient entries is the cn attribute. For all other object classes, the RDN is the uid attribute. In addition, each entry (node) is uniquely identified in the directory information tree by its Distinguishing Name (DN), which is the sequence of RDNs in the tree path from the root to the current entry. The RootEntry of the directory is "st=crete, o=health, c=gr." Note that the present directory may be linked to other directories, which correspond to other regions. For example, the PCDD in the region of Epirus has root entry "st=epirus, o=health, c=gr." The two main branches of the directory information tree are SystemType and HealthcareRecord and maintain entries relevant to feeder systems and patient data, respectively.
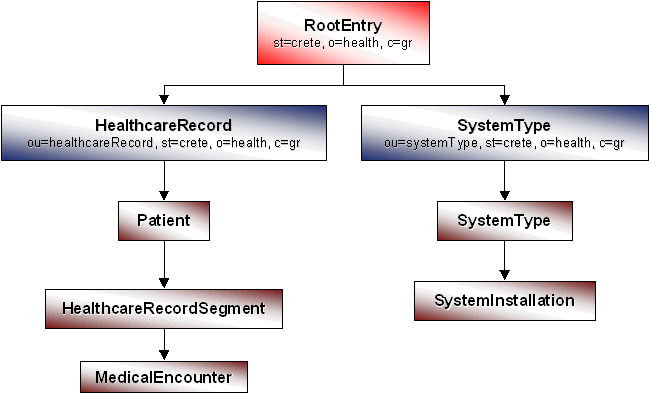
Figure 9: Directory Information Tree Supported by the PCDD.
A possible SystemType branch appears in Figure 10. Observe in the figure that the root of the subtree (SystemType) is marked with its DN, namely "ou=systemType, st=crete, o=health, c=gr," while all other nodes are marked by uid, the RDN of the specific entries. The name and version of the clinical information system (e.g. PHCCIS v1.0) identify SystemType entries (i.e. PHCCIS v1.0). SystemInstallation entries are identified by the geographic location and organizational unit, where the feeder system has been installed (e.g. SPILI RETHIMNON PHC).
The HealthcareRecord branch of the directory information tree organizes patient-related data. Patient entries express a unique PCDD-wide patient identity. Each patient is uniquely identified in the directory by four attributes, namely lastName, firstname, parentName, birthDate, and gender. This is due to the fact that there is no single region-wide person identification. Thus, if two patients have the same sequence of values for these attributes, their EHCR segments are classified under the same Patient entry. Even this seemingly simple solution, however, raises several problems. First, with low probability, there will be a single Patient entry for two physically different persons. Second, several systems do not keep parentName or full birthDate data. Other systems, especially those that deal with emergencies, do not always have even the lastName registered in the database. PCDD deals with these problems on a case by case basis. If a system does not have lastName data in a record, the record is considered incomplete and the corresponding data is not inserted in the directory. If just the parentName does not exist in the record, then the indication “UNKNOWN” is entered as the value of the attribute. birthDate has also several problems associated with it. The directory stores birthDate attribute values in the form dd/ mm/ yyyy. In small villages, however, elderly citizens do not recall their exact birthDate; in the best case, they may recall the year approximately. The directory stores dates as strings, thus, birthDate "dd/ mm/ 1933" means that only the year of birth is known.
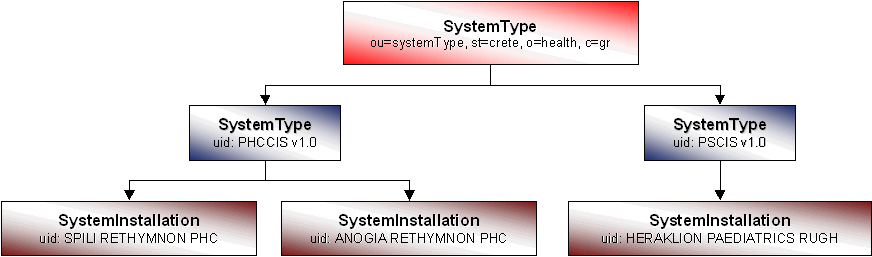
Figure 10: System Type Subtree In A Directory Shows Two Different Systemtypes Entries: PHCCIS V1.0 And PSCIS V1.0. In This Example, PHCCIS V1.0 Has Two Installations, While PSCIS V1.0 Has One.
For each EHCR segment of a given patient, a new HealthcareRecordSegment entry is placed under the corresponding Patient entry. Thus, the subtree of the directory information tree rooted at a specific Patient entry has as many branches as the feeder systems that store EHCR segments of that patient. The clinical meta-data of a medical encounter appear in the MedicalEncounter leaves of the subtree rooted at the corresponding HealthcareRecordSegment entry. A possible Patient subtree appears in Figure 11. In the figure, the Patient entry (root node) is marked with its DN (i.e. "cn=Chronaki Catherine Eleftherios 15/9/1978, ou=healthcarerecord, st=crete, ou=health, c=gr"), while all other entries are marked by their RDN (i.e. uid=…). HealthcareRecordSegment entries are partially identified by the patientID in the feeder system (e.g. PHCCIS v1.0 – SPILI RETHIMNON PHC – 39). Note that for a HealthcareRecordSegment entry to be valid, the corresponding SystemType and SystemInstallation entries should be present in the directory. Their ID also identifies MedicalEncounter entries in the feeder system.
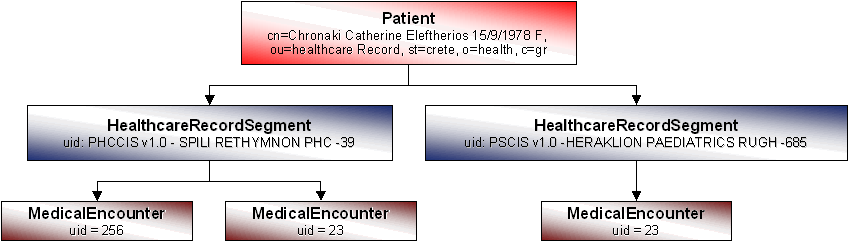
Figure 11: Patient Subtree in A Directory Shows A Patient Who Has Visited Twice the Spili PHC and Once the Pediatrics Clinic at the RGUH of Crete.
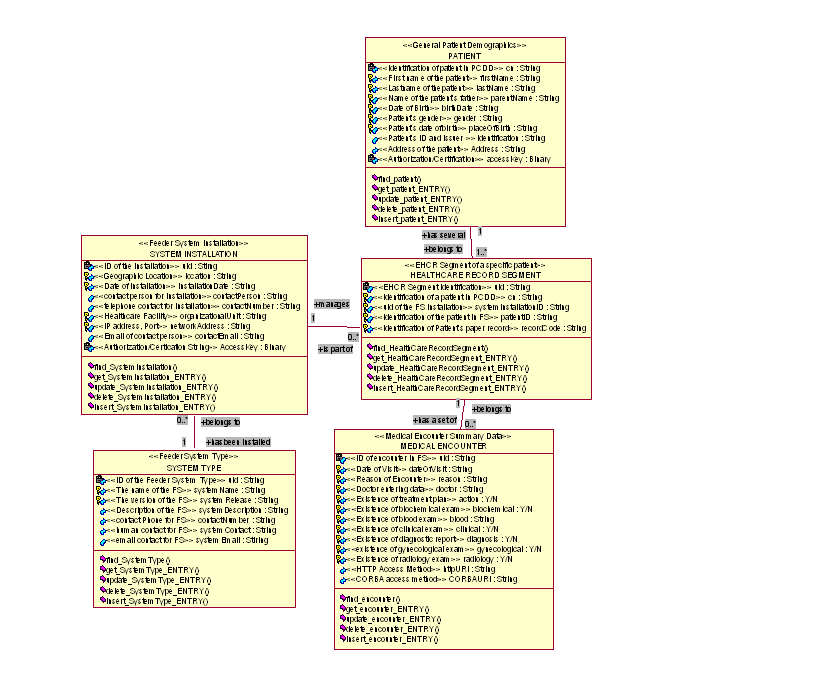
Figure 12: UML Class Diagram of the Entry Types in the Directory.
SystemType entries identify clinical information systems uniquely by their name and version. Additional attributes that may be updated, are a description of the system and information on the person responsible for the software. Figure 13 shows an example SystemType entry.

Figure 13: Example of A Systemtype Entry in the PCDD.
Feeder systems are installations of clinical information systems of known SystemType, in a healthcare facility. They are represented in the directory by SystemInstallation entries. The concatenation of the location and organizationalUnit identify the SystemInstallation entry of a feeder system. Observe that feeder systems correspond to SystemInstallation entries and not SystemType entries. For example, the SystemInstallation entry of PHCCIS v1.0 in SPILI RETHIMNON PHC and the SystemInstallation entry of PHCCIS v1.0 in ANOGIA RETHIMNON PHC are two different feeder systems, which are instances of the same SystemType. The fact that a specific SystemType entry may have been installed at multiple organizational units, is shown in the conceptual model with the relation between the SYSTEM TYPE and SYSTEM INSTALLATION classes. Authorization and certification of the feeder systems that have the right to access and update the PCDD is provided by a unique accessKey that is assigned to each feeder system. An example SystemInstallation entry appears in Figure 14.
Figure 14: Example of A Systeminstallation Entry In The PCDD.
Besides patient identification data, Patient entries in the directory include optional demographics attributes. These are placeOfBirth, identification, and address. The value of the identification attribute includes both the unique IDs and the issuing authority within brackets, separated by commas. Since attributes allow multiple values, multiple identifications of a patient within an information system can be supported. Just like a SystemInstallation entry, a Patient entry includes an accessKey, a special attribute for authorization and certification purposes. A sample Patient entry appears in Figure 15.

Figure 15: Example of A Patient Entry in the PCDD.
A HealthcareRecordSegment entry corresponds to an EHCR segment of a patient. The attribute uid identifies HealthcareRecordSegment entries. The value of uid is the concatenation of the attributes systemInstallationID and patientID separated by "-". PatientID is the ID of the patient in the feeder system, while systemInstallationID is the location and name of the organizational unit. Note that the insertion of a new HealthcareRecordSegment entry requires the existence of the corresponding feeder SystemInstallation entry in the directory. The attribute recordCode refers to the paper record of patient in the organizational unit, if such a record exists. A sample HealthcareRecordSegment entry appears in Figure 16.

Figure 16: Example of A Healthcarerecordsegment Entry in the PCDD.
A MedicalEncounter entry corresponds to a single contact of a patient with a healthcare facility. Multiple medical encounters may be part of a single episode, i.e. the treatment of a long-term problem. This viewpoint is not supported by the current version of the directory information model. The identification attribute of MedicalEncounter entries is uid, the identification of the particular encounter within its feeder system. Other important encounter-related information is the date and time of the encounter and the attending physician (doctor). The rest of the attributes refer to the SOAP model [Tonnesen96]. Reason (e.g. “Feeling of Arrhythmia”) refers to the subjective symptoms. Biochemical, blood, clinical, gynecological, radiology are Y/N indicators of whether the corresponding clinical objects were produced during the encounter. All these indicators refer to the objective signs (physical signs and test results). “N” refers to absence, while “Y” refers to presence of examination results. Diagnosis indicates whether a diagnosis has been associated with the contact. In specific, diagnosis refers to the assessment and the rationale for a selected plan (a summary of the patient's condition or course of illness); again “N” refers to absence, while “Y” refers to presence of diagnosis. Finally, action is a Y/N indicator of whether certain actions have been prescribed. Apart from the attribute reason, all the other attributes referring to the SOAP model, simply indicate the existence of the relative information. An example MedicalEncounter entry appears in Figure 17.

Figure 17: Example of A Medicalencounter Entry in the PCDD.
For the time being, human-mediated, HTTPuri, and CORBAuri are the only supported methods to access primary clinical data from feeder system installations. As it has already been presented in Figure 5, access links may be always or temporarily available. In addition, according to the available network bandwidth, some of these access links may be faster compared to others, while certain EHCR segments may be temporarily inaccessible. In this case, the only possible access to the clinical data is through human mediation through the doctor that serviced the specific encounter. Interoperability of PCDD with the HRM enables tracing further information on the specific healthcare professional.
Several attributes that were originally proposed for inclusion in the MedicalEncounter object class, were intentionally left out from the current version. These include referringPhysician to support referrals and typeOf Visit (initial, follow-up, active, etc.) to support a possible problem-oriented view of the EHCR. Also, currently the directory supports access mediation up to the MedicalEncounter level. Mediating fine grain access to the feeder information systems, i.e. at the clinical object level, was also left out of the current version of PCDD. Such extensions to PCDD are expected to increase the level of information integration at the cost of a more complex directory structure. They will also lead to a more active form of a directory.
Figure 18 shows the architecture of the PCDD. In the core of the PCDD middleware lays the X.500/ LDAP directory. The PCDD server is a CORBA server that exports a number of public and stable IDL interfaces to be used by other middleware and user-oriented services. The PCDD server communicates with the directory using the LDAP protocol [Yeong95]. The current IDL interfaces of the PCDD server are the PCDD Query IDL, the PCDD Update IDL, the PCDD Admin IDL, and the PCDD Statistics IDL. The PCDD Query IDL enables an encounter-centered view of the Virtual EHCR (see Section 6.1). The PCDD Update IDL facilitates the update of data associated with a specific feeder system. Through the PCDD Admin interface, new feeder systems are incorporated into the directory. Finally, the PCDD Statistics IDL enables a service that draws statistics on medical encounters throughout the region based on anonymous data provided by the PCDD (see Section 6.2). Access to the PCDD server is facilitated through the use of the IIOP protocol. The IDL interfaces are further discussed in Section 4.3.1.
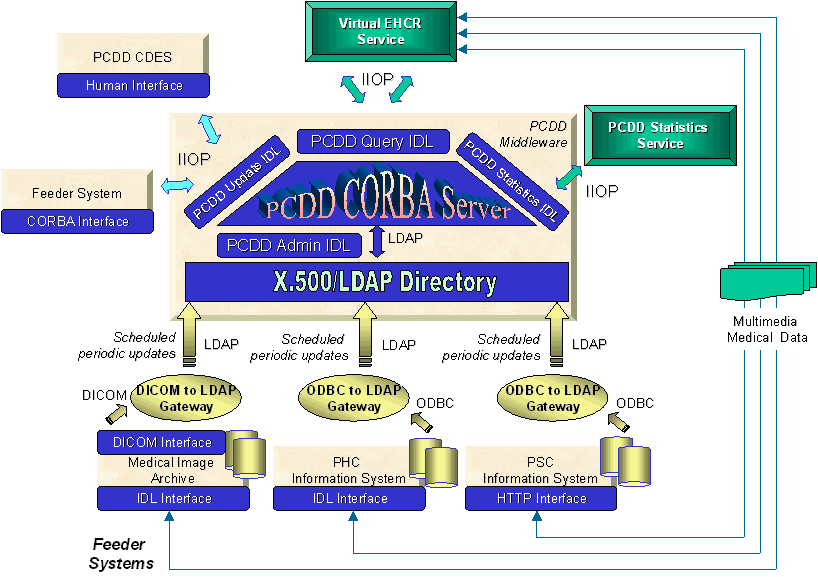
Figure 18: PCDD Maintains Summary Data on the Distributed EHCR Segments. The Technological Approach Includes CORBA For Inter-Process Communication, X.500/ LDAP For The Directory Infrastructure, And Dedicated Gateways For Scheduled Periodic Updates.
In general, feeder systems update the directory in a bulk-load fashion. Each feeder system is associated with a dedicated gateway that facilitates data extraction from the feeder system. A view of the information model in the clinical information system that conforms to the PCDD information model, facilitates data extraction. Gateways get data from the feeder system, map it to the model of the directory, and translate it into LDAP statements, which are stored in a standard LDAP modify file. A Perl script [Srinivasan97] is used to update the directory. Since feeder systems are in general heterogeneous, this gateway may take different forms. Possibilities include but are not limited to ODBC/ LDAP gateways and DICOM/ LDAP gateways. Scheduled periodic updates are further discussed in Section 4.3.3.
Directory updates are also feasible through the PCDD Clinical Data Entry System (CDES). The PCDD CDES is a special case of a feeder system and may take the place of a clinical information system if one does not exist. The PCDD CDES is further discussed in Section 5.5 together with other feeder systems in the PCDD federation. Section 4.3 describes the various use cases that involve PCDD middleware: IDL interfaces (Section 4.3.1), the introduction of a new feeder system into the federation (Section 4.3.2), periodic on-line updates (Section 4.3.3), and access to clinical objects in feeder systems (Section 4.3.4).
Figure 19 shows the use case scenarios that involve the PCDD. The End User accesses information in the directory through user-oriented services that use the PCDD Query interface. In addition, any of the PCDD Administrators can incorporate new feeder systems in the federation using the PCDD Admin interface. Feeder Clinical Information Systems may use special components that feed data into the directory through the PCDD Update interface. They may also use the PCDD Query interface as part of more complicated use cases, related to the correlation of patient identities in feeder information systems and the coordinated execution of complicated tasks.
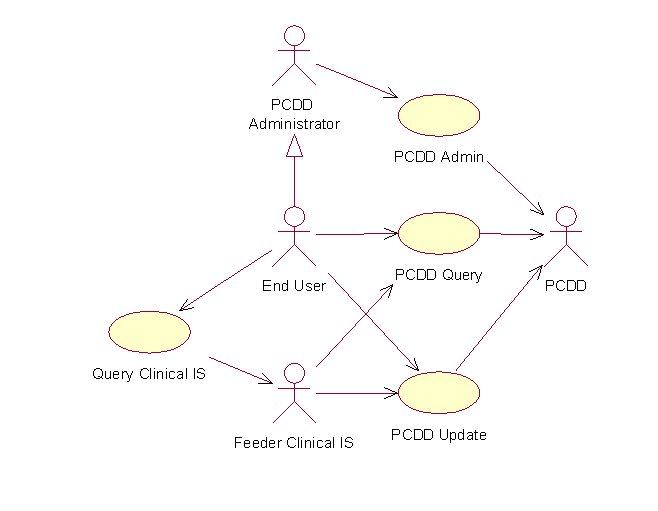
Figure 19: UML Use Case Diagram Demonstrating the Basic Operations That Involve the PCDD.

Figure 20: The PCDD Module Includes General Data Structures; The PCDD_QUERY, The PCDD_UPDATE, The PCDD_STATS, And The PCDD_ADMIN Interfaces, Which Are Common To All The PCDD IDL.
The PCDD Query interface of Figure 21 (PCDD_QUERY) provides an encounter-centered view of a patient’s data. Through this interface, the Virtual EHCR service may search for the distributed EHCR segments of a patient, select one, and retrieve all the associated medical encounters. The query model supported by the interface is simple. The user uses the find_patient() function, which takes as argument a Patient entry. The character "*" facilitates wildcard string matching. The function returns a sequence of Patient_IDs. The function get_patient_ENTRY() takes as argument a Patient_ID and returns the associated Patient entry. The same philosophy applies to all other entry types supported by PCDD. The HealthcareRecordSegment entry class is a special case, since it does not provide a get_ function.

Figure 21: The PCDD Query (PCDD_QUERY) Interface.
The PCDD Update interface of Figure 22 (PCDD_UPDATE) is used to modify, add and/ or delete data relevant to a specific feeder system. The functions get_SystemInstallation_ENTRY() and update_SystemInstallation_ENTRY() respectively retrieve and update the attributes of the corresponding SystemInstallation entry.
The function insert_HealthcareRecordSegment_ENTRY() inserts a HealthcareRecordSegment entry for the patient if it does not exist in PCDD. If a Patient entry does not exist in the directory, a Patient entry is inserted before the HealthcareRecordSegment entry.
The function update_patient_ENTRY() updates the demographics of the patient in te directory. The function delete_HealthcareRecordSegment_ENTRY() deletes the healthcareRecordSegment entry of the patient together with all the associated medicalEncounter entries. The function insert_encounter_ENTRY() inserts the data for a MedicalEncounter entry in the directory. Finally, the function update_segment() enables the batch update of the directory using an LDAP file. If the LDAP file is empty, data from this feeder system is removed from the directory.

Figure 22: The PCDD Update (PCDD_UPDATE) Interface.
The PCDD Administration Interface of Figure 23 (PCDD_ADMIN) is responsible for the management of the directory. It enables a set of privileged operations such as the update or backup of the data associated with a specific SystemInstallation, and the inclusion of a new feeder system into the federation. It also enables the modification of contact data associated with a particular SystemType.

Figure 23: The PCDD Administration (PCDD_ADMIN) Interface.
The PCDD Statistics interface of Figure 24 (PCDD_STATS) facilitates drawing statistics on the contents of the directory. The main characteristic of this interface is that it provides bulk access to the encounter-related contents of PCDD without patient identification information. Thus, an application that uses this interface can neither update the contents of the directory nor access patient identity information.

Figure 24: The PCDD Statistics (PCDD_STATS) Interface is used For the Extraction of Statistical Data Using Contents of the PCDD.
The feeder systems that belong to the PCDD federation are geographically distributed, heterogeneous, and autonomous. Each feeder system has its own user interface as well as other means of access to the information it provides. In addition, each feeder system is an instance (SystemInstallation) of a SystemType. The introduction of a feeder system of unknown system type into the federation is a process that requires human mediation and involves five steps: (a) concept mapping, (b) design of an export view, (c) implementation of a data extraction gateway, (d) registration of the feeder SystemType and SystemInstallation inside PCDD, and (e) the scheduling of periodic on-line directory updates. The overall process is outlined in Figure 25.
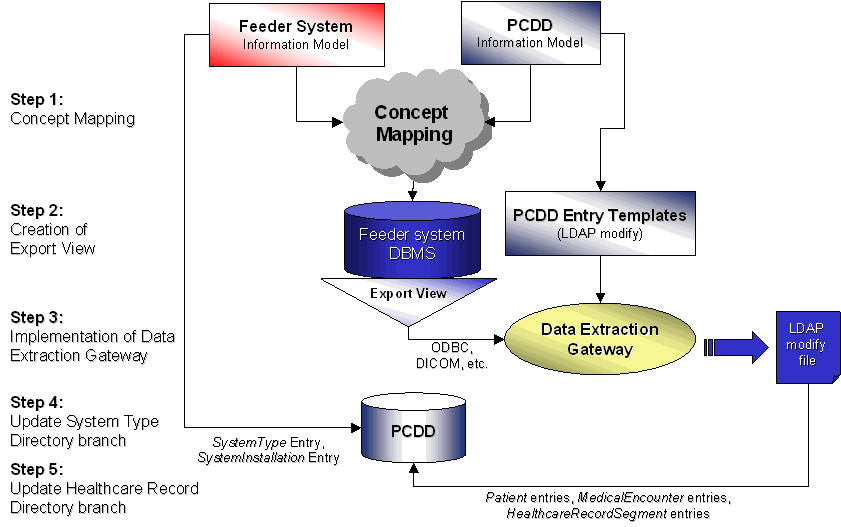
Figure 25: Introducing A Feeder System of Unknown System Type to the PCDD Federation.
The fact that each SystemType entry has its own database model requires that semantic interoperability issues need be dealt prior to any unknown feeder system introduction to the PCDD federation. Concept mapping involves examining the correspondence of concepts in the information model of the feeder system and PCDD. Actually, PCDD concepts may be classified in four groups: Patient, Encounter, Clinical object, and Access Method. These concept groups appear in Figure 26.
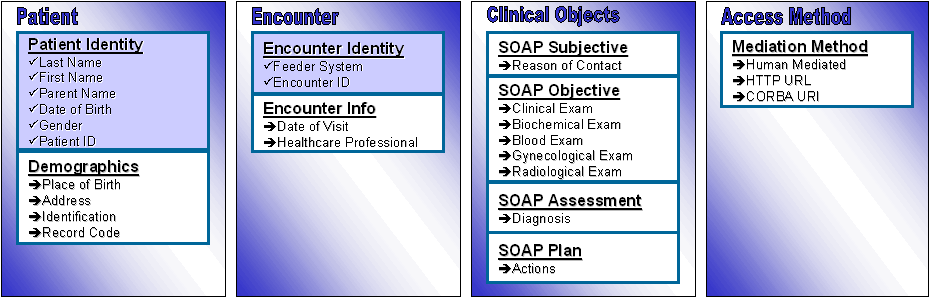
Figure 26: Concept Groups of the PCDD Information Model.
Mapping a minimal set of concepts in the Patient group is necessary for the introduction of the clinical information system into the federation. In specific, the system should provide a notion of patient identity. In the current version of the directory this means that it should provide minimal demographic data on each patient (i.e. firstName, parentName, lastName, gender, birthDate), as well as the ID of the patient record in the feeder system. The additional demographics in the PCDD model may be provided by the feeder system if they are part of its information model. Such information enables the PCDD to provide location information on the EHCR segments of a particular patient. Further information on that segment may be provided through human mediation. Recall that the directory maintains information on a contact person for each feeder system (i.e. SystemInstallation entry). Thus, a doctor accessing the PCDD may call or send e-mail to the person responsible for a particular EHCR segment.
The Encounter concept group corresponds to a contact of a patient with a healthcare facility. The clinical information system should provide at a minimum, the ID of the encounter in the feeder system. Additional encounter concepts include the date of the encounter and the healthcare professional(s) that took part in the contact. This enables PCDD to answer questions on the contacts of a patient with a healthcare facility. It does not, however, allow answering queries on particular medical problems or diagnostic examinations.
The Clinical Objects concept group involves largely conformance to the SOAP model as it has been employed in PCDD. This essentially means establishing correspondence with the notions of “reason of contact,” “examinations,” “diagnosis,” and “treatment.”
The Access Method concept group does not relate directly to the information model of the feeder system. It relates to the configuration of the feeder system and the methods of gaining access/ control to further information in it. So far the directory can mediate human-mediated, HTTP URLs, and CORBA URIs access methods to feeder information systems.
The information produced during concept mapping is used to create an export view of the feeder system. This view is employed to extract data from feeder systems of that type, fill in standard LDAP modify templates, and store them in an LDAP file.
Different feeder system support different means of access. The most common means of access to a feeder system is through a DBMS server. Alternative access methods include the use of proprietary servers, or even the WWW. So far, an ODBC to LDAP gateway has been implemented that enables data extraction from database systems (so far Sybase, Oracle, and SQL Anywhere) using the ODBC protocol. In addition a DICOM to LDAP gateway has been designed that enables data extraction from a DICOM medical image archive.
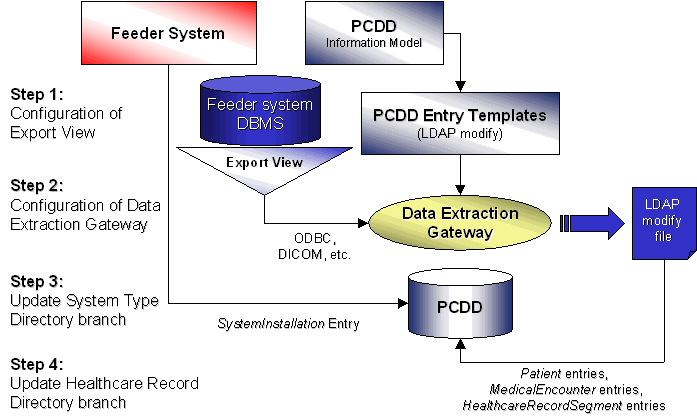
Figure 27: Introducing A Feeder System of Known System Type to the PCDD Federation.
The introduction of a feeder system that is of known system type into the federation, is rather straightforward. It involves configuration of an existing export view and data extraction gateway and registration of the feeder system installation into PCDD. The process is outlined in Figure 27.
As new feeder systems are introduced into the federation, the tool chest of export views and data extraction gateways is expected to become richer and support a wider range of means of access. Note that each of these gateways encapsulates a semantic mapping core in the form of the export view and supports standard interfaces. Thus, even though differences in the export view require a dedicated data extraction gateway for each feeder system, the code in existing gateways may be reused.
Any information service is as good as the content it provides. Good content means consistent, accurate, up-to-date information. For PCDD, this means service quality guarantees on the accuracy of the patient data that it delivers. Since directory technology provides the infrastructure for the deployment of large indices for information that is mostly read, service quality with respect to PCDD is largely a deployment issue. As a service quality analogy, consider the metaphor of the phonebook. If a new phonebook is released every day, the information in the phonebook will be at most 24 hours old, and that determines the quality of the service it provides.
Responding to the need for consistency and accuracy, service quality in PCDD is based on scheduled periodic on-line updates. The PCDD update architecture appears in Figure 28. The basic components of the architecture are the directory update agent, the various data collection agents, and the shared workspace. The directory update agent is responsible for updating the directory on a schedule. Each data collection agent is responsible for the activation of a data extraction gateway tied to a particular feeder system on the schedule provided by the directory update agent. Finally, the shared workspace serves three functions: (a) it is a repository for the LDAP modify files produced by data extraction gateways, (b) it serves as a blackboard where update schedules are posted, and (c) it maintains accounting information regarding the operation of data extraction gateways.
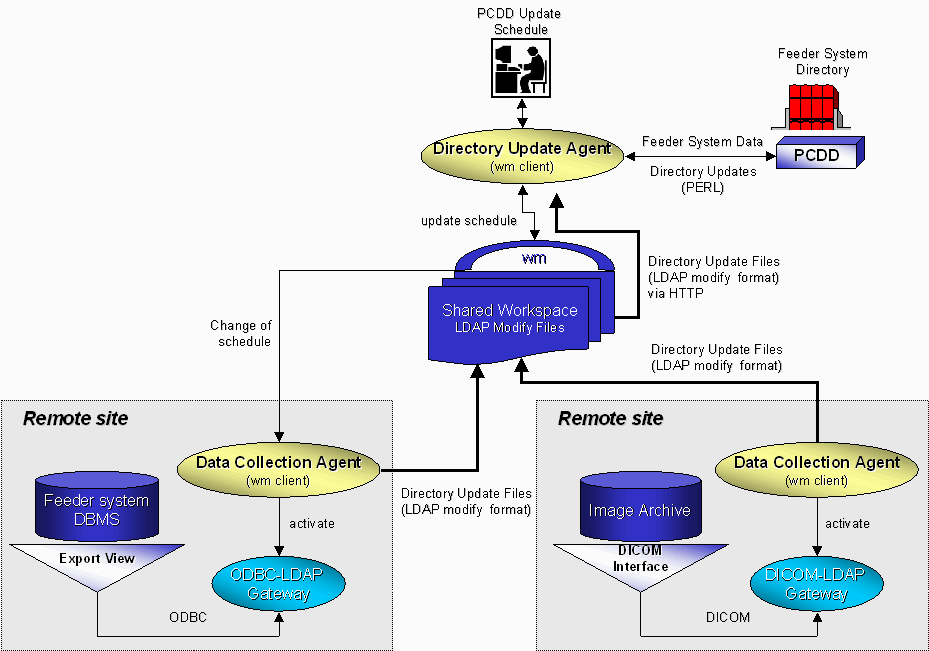
Figure 28: The PCDD Update Architecture.
The overall architecture is enabled by the collaboration infrastructure of WebOnCOLL [Chronaki97] [Chronaki98a]. A WebOnCOLL server (wm) manages a workspace shared among the directory update agent and the data collection agents. Both the directory-update agent and the data collection agents are clients of wm and receive notifications on updates of the shared workspace. For data collection agents, such events are schedule updates. For the directory update agent, such an event is the creation of a new directory update file by one of the data collection agents.
The directory update agent interfaces the human administrator of the directory to get scheduled updates and communicate accounting information. The shared workspace serves as the persistent memory of the directory update agent. It gets from the shared workspace accounting information and LDAP modify files. It uses accounting information to create reports for the directory administrator and LDAP modify files to update the directory using a Perl script. It stores in the shared workspace the output of the Perl script for accounting purposes, and the update schedule set by the directory administrator. The directory update agent also communicates with the directory using the PCDD Query interface to locate feeder systems information stored in SystemInstallation entries. This information is used to create and coordinate data collection agents. The directory update agent provides this functionality by being a client of both the wm and the PCDD server.
The Perl script used to update the directory takes as argument the identification of the SystemInstallation entry and the LDAP modify file. It locates the SystemInstallation entry in the directory and verifies the accuracy of the access key in the LDAP modify file. Then, it updates PCDD using the LDAP modify directory utility. Since the execution of the script does not stop if an entry already exists in the directory, updating the directory exhibits the following behavior. If the patient already exists in the PCDD and has a HealthcareRecordSegment entry for the particular feeder system, the directory is updated with new encounters. If a patient exists in the PCDD, but does not have a EHCR segment for that feeder system registered in PCDD, a new HealthcareRecordSegment entry is created under the existing Patient entry. If a patient does not exist in the directory, new Patient and HealthcareRecordSegment entries are created first, and then the directory is updated with MedicalEncounter entries of the specific patient. Prior to each scheduled update, the directory is backed up and its contents are exported in LDIF.
In contrast to the directory update agent, data collection agents are rather general purpose. Their sole goal is to activate data extraction gateways on schedule, collect the results (LDAP modify files), and post the results in the shared workspace. Data collection agents are very similar to the Outbox designed in the context of the Telecardiology service described in [Chronaki98b].
Alternatives to this basic update scheme are spontaneous and push updates. Spontaneous updates occur when a healthcare practitioner actively updates the directory and wishes that the update be reflected in PCDD as soon as possible. This is a special directory update case, which will be provided only if users consider it necessary. The interface of the directory update agent with the clinical information system may be implemented through the MAPI protocol. The user may use the common “File|Send” paradigm for sending information on a particular encounter to the directory. Specialized directory update agents, who utilize the PCDD Update and PCDD Query interfaces and interact with the shared workspace, can implement this functionality. This update agent uses the PCDD Update IDL to directly update the directory and acts as a wm client to enable accounting and auditing. Note, however, that such an approach complicates the overall management of the directory at the cost of a more active behavior. Another concern is the fact that spontaneous updates violate the metaphor of the telephone book, released on regular intervals, as it is upheld by the directory.
Push updates occur when each feeder system controls its PCDD update schedule. The human operators of the feeder systems decide when and which part of current contents of the information system to export. The advantages of using a push update scheme are: (a) time sensitivity – a feeder system may update the directory only with the new entries in the information system (b) response time - the feeder system can respond faster to schedule changes, (c) selective update – the operators may decide which part of the data to export. The main disadvantage is additional complexity. Under a push update schema, it is also hard to sustain, uniformly, a high level of content quality.
For the moment, two different ways of on-line access of clinical objects in the distributed EHCRs have been investigated: (a) through HTTP, and (b) through CORBA. For those healthcare facilities that have a web server, certain modules have been developed for accessing visit information (read-only). For others that do not have access to a web server, CORBA IDLs offer the solution. Note that both web, as well as CORBA servers need not be located physically close to the clinical information systems. Some other clinical information systems that do not want to offer direct access to their data, but they still want to feed clinical data into PCDD, may provide just contact data for anyone who seeks further information. Of course a prerequisite for on-line access is for the clinical information systems to be accessible 24-hours a day.

Figure 29: Generic IDL Interface for Accessing Clinical Objects in Feeder Systems.
So far, three SystemTypes have been introduced into the PCDD federation. These are the Primary Healthcare Information System v1.0 (PHCCIS v1.0), the Pediatrics Surgery Clinic Information System v1.0 (PSCIS v1.0), and the Health Emergency Coordination Center Information System v1.0 (HECC v1.0). The initial planning has been carried out for the introduction of a medical image archive accessible through a DICOM interface (HyARC v1.0). The following Sections describe briefly each of the SystemTypes, outlines the conceptual mapping of each information model to PCDD and describes the experience gained from the incorporation process.
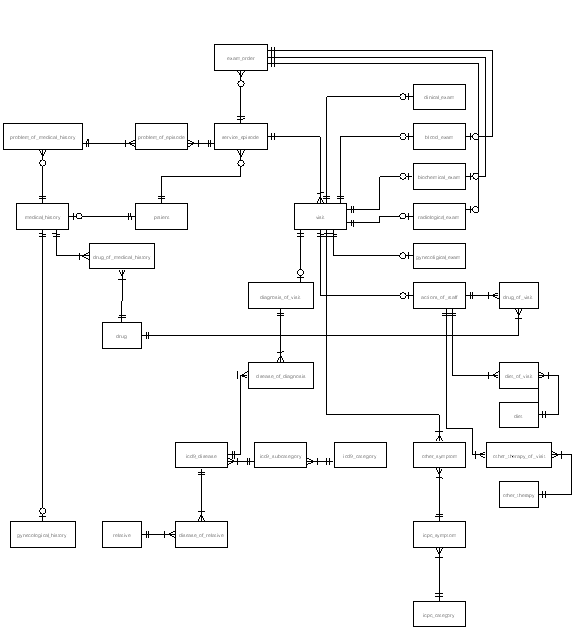
Figure 30: PHCCIS V1.0 Entity Relationship Diagram.
The PHCCIS v1.0 is an information system that is currently deployed in nine Primary Healthcare Centers in the region of Crete (as of October 1998) and implements a generic and broad-spectrum healthcare record to be used by GPs in primary healthcare centers. More than 30 forms provide access to patient data and support Query by Example. That means that even complex queries are supported (by means of wild chars, binary operands, etc.). In addition, concise views of the data can be exported to commercial software (like MS Access for example).
PHCCIS provides two views of its EHCR segment. The visit-oriented view of a patient record consists of a list of encounters/ visits and is implemented as a 2-dimension table. Each row represents a distinct encounter/ visit. For each encounter/ visit, the relevant examinations, investigations, diagnosis or assessments are checked. Specifically, a PHCCIS encounter may contain a number of examinations such as a clinical examination, a gynecological examination, a biochemical analysis, a blood analysis or a radiographic study, as well as a diagnosis and a segment with the therapeutic management of the healthcare personnel and the treatment plans.
In the problem-oriented view, the patient record is divided into a series of sections, each of which is given the heading "problem" or more generally "previous diagnosis" [Bainbridge96]. The “problem” may be defined by an ICD9 code or described by free text. Items and data in the patient record are grouped under one or more problem (previous diagnosis) headings. When a problem is selected, information relevant to that problem is viewed. Every problem is associated with one or more episodes. An episode may be (a) an episode of a problem: Many health problems are not continually active, but they exhibit a cycle of activity. The period where the problem is reported to be active may be defined as an episode of the problem, (b) a service episode: a collection of events aggregated during an interval bounded by start and stop times, (e.g. a series of relevant encounters/ visits).
The main entities of the Database schema are presented in the Entity – Relationship Diagram (ERD) of Figure 30. The conceptual mapping of PCCIS to the directory model was straightforward since its information model fits nicely with the SOAP model. Mapping between PHCCIS entities and PCDD entities is facilitated by means of certain views, corresponding to the PCDD HealthcareRecordSegment (i.e. patient in Figure 30) and MedicalEncounter (i.e. visit in Figure 30) entities. Their mapping to the PHCCIS data model is depicted in Figure 31.
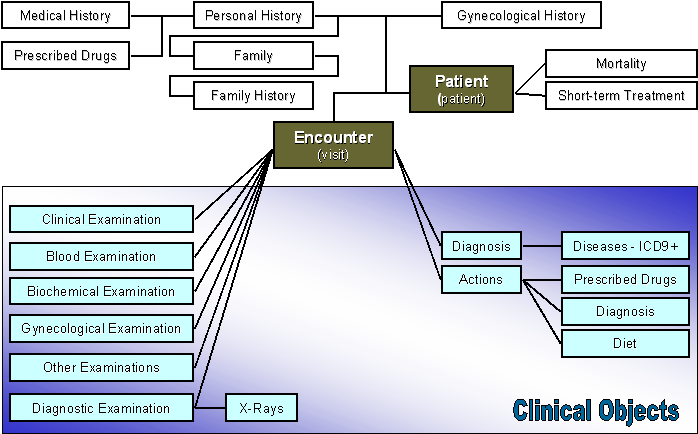
Figure 31: Conceptual Mapping Of PHCCIS V1.0 to the PCDD Information Model.
So far, two feeder systems of the PHCCIS v1.0 SystemType, have joined the PCDD federation. These feeder systems correspond to the installations of PHCCIS at the PHC of Spili (Rethymnon prefecture) and at the PHC of Anogia (also in the prefecture of Rethymnon). Each of these feeder systems supports native system access through HTTP URLs.
PSCIS v1.0 has been designed to assist the physician in registration, storage and retrieval of clinical cases in a pediatric surgery clinic. The operational workflow of the system is based on a hierarchical linkage of relevant information items and functions that concern: patient’s demographic data U contacts U actions U and treatment. Input and registration of clinical data, follows and implements de Dombal’s clinical protocol for Acute Abdominal Pain [Dombal91]. One of the basic characteristics of the system is emphasis on workflow and state.
The internal structure of the PSCIS consists of four database tables: K_KARTELA, K_TRANSACTION, K_TRANSACTION_ITEM, and K_KOILIAKO_ALGOS. The conceptual model of this schema is shown in Figure 32.

Figure 32: Main Database Tables in PSCIS V1.0.
K_KARTELA holds demographic data concerning a specific patient. K_TRANSACTION keeps contact (medical encounter) information for a patient (the same patient may have more than on contacts). K_TRANSACTION_ITEM keeps track on the acts that followed the specific contact, and finally K_KOILIAKO_ALGOS keeps information concerning the examination associated with the specific act. Concept mapping of the PCSIS v1.0 information model to PCDD is shown in Figure 33.
Concept mapping is straightforward except in the case of a medical encounter, where the basic information is stored in the K_TRANSACTION_ITEM and K_KOILIAKO_ALGOS, while some additional data necessary for entries of this type are stored in the K_KARTELA and K_TRANSACTION tables.
The main issue that was raised in the conceptual mapping of PSCIS to PHCCIS, relates to the fact that the information model of PSCIS is in a sense problem-oriented and includes workflow information. A contact in PSCIS has a state. This information is not reflected in the current information model of PCDD. It is expected that a future version of PCDD, which expresses the notion of medical problem or episode as a sequence of related contacts coupled with state information on the encounters, will exploit more of the information in PSCIS.
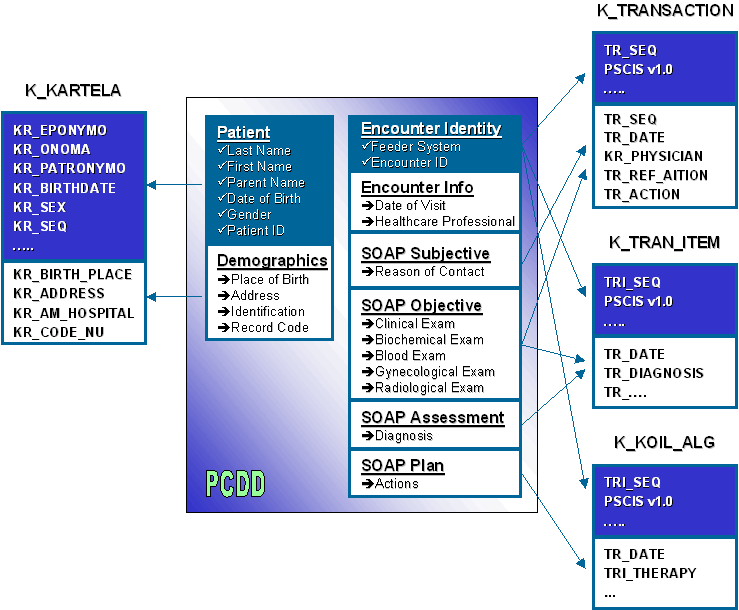
Figure 33: Conceptual Mapping PCDD to PSCIS Mapping.
The access method supported by PSCIS is HTTP. PSCIS is a web-enabled information system. Through appropriated URLs, authorized personnel may access medical encounter information using the native web-interface of PSCIS. Note that even though the information exported in PCDD appears in terms of PCDD concepts, once an HTTP URL is followed to a specific medical encounter, the retrieved clinical concepts used are those of PSCIS. Thus the term "contact" is used, instead of the term "medical encounter," and so on. This is reasonable since the role of PCDD is just that of an access mediator. An approach that provides a higher degree of semantic uniformity, would require the translation of the terms used in PSCIS into a commonly agreed terminology. Activities such as LQS and COAS are expected to play a critical role in this setting.
HECC IS v1.0 is operational for at least a year, at the Health Emergency Coordination Center (HECC) in Heraklion, Crete. Operators at the HECC record calls, and ambulance drivers record clinical data, such as vital signs that are produced on the ambulance.
HECC v1.0, as an information system, addresses the needs of pre-hospital emergency care and in that sense it is a special case of a clinical information system. All the other feeder systems that have been considered so far, are patient-centered. In contrast, all information in HECC is organized around the notion of an emergency call, since in a considerable number of emergency cases, the demographics of a patient is unknown at the time of the emergency call.
The information model of HECC has been mapped into PCDD on the assumption that an emergency incidence corresponds to a MedicalEncounter. Figure 34 shows the correspondence of basic HECC IS incident-related concepts, to PCDD concepts. This correspondence has been used to create the SQL-to-LDAP gateway. Patient demographics were a big issue, since operators rarely record the full set of demographics used for patient identification in PCDD. They fill out lastName, firstName in the user interface field allocated for lastName, and they never fill out the parentName. The birthDate may be deduced from the date and age fields. To reduce inconsistencies, PCDD indexes only those records in which lastName and firstName have been recorded even in the same field. Since the patient records in HECC do not include a value of parentName the keyword term “UNKNOWN” has been to indicate lack of the relevant information. Regarding clinical objects in the objective part of the SOAP, an emergency incident folder includes only vital signs and relevant observations. These are considered part of the clinical examination data.
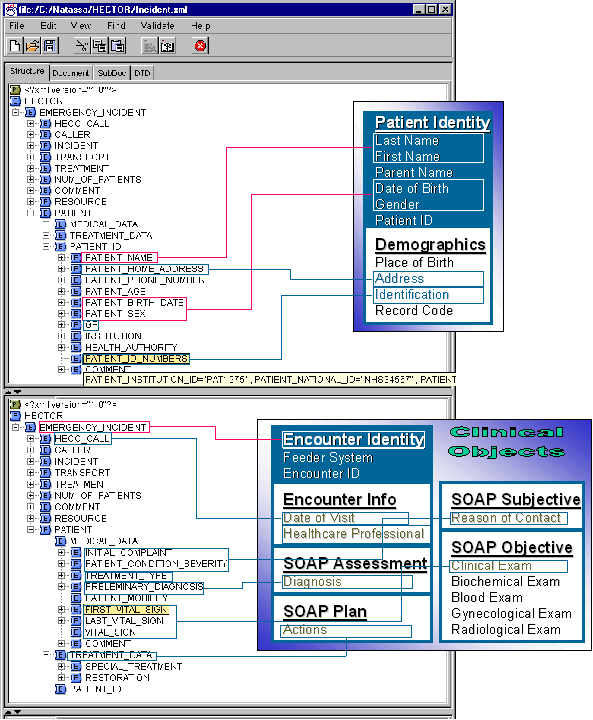
Figure 34: Mapping Of Basic HECC Concepts Expressed in XML, To the PCDD Information Model.
HyARC v1.0 is DICOM-compliant image archive that operates as a repository for medical images and is accessible via the DICOM protocol. The introduction of HyARC into the federation is complicated by the fact that access to this repository is not ODBC-based like the feeder systems that have been considered so far.
The notion of a DICOM study is subject to semantic variations according to the medical modality of the images in the archive. The medical encounter concept has been associated with the notion of a DICOM study. The effect of this association is that DICOM studies of a patient that have been created on the same visit of a patient to a radiology clinic are considered as separate encounters. The operation of the DICOM-to-LDAP gateway is relatively simple. The gateway retrieves the identification and date of all studies of all patients in the archive, and uses LDAP templates to translate this information to an LDAP update file. The process goes as it follows. First the gateway operates as a DICOM Patient-Root Service Class User (SCU) and addresses a query identifier to the archive. This identifier queries the image archive on patients whose name is anything (i.e. “*”) and requests the retrieval of the name, ID, birthdate, and sex, for all patients matching the query, i.e. for all patients in the archive. The gateway uses LDAP modify templates to store the retrieved information in Patient entry templates. At the same time, the gateway prepares a list with all patientIDs in the archive. Then, for each patientID, the gateway addresses a query identifier to archive, which requests all studies of each patient in the archive. Again, from the results the gateway fills in MedicalEncounter entry templates and stores them in the update file.
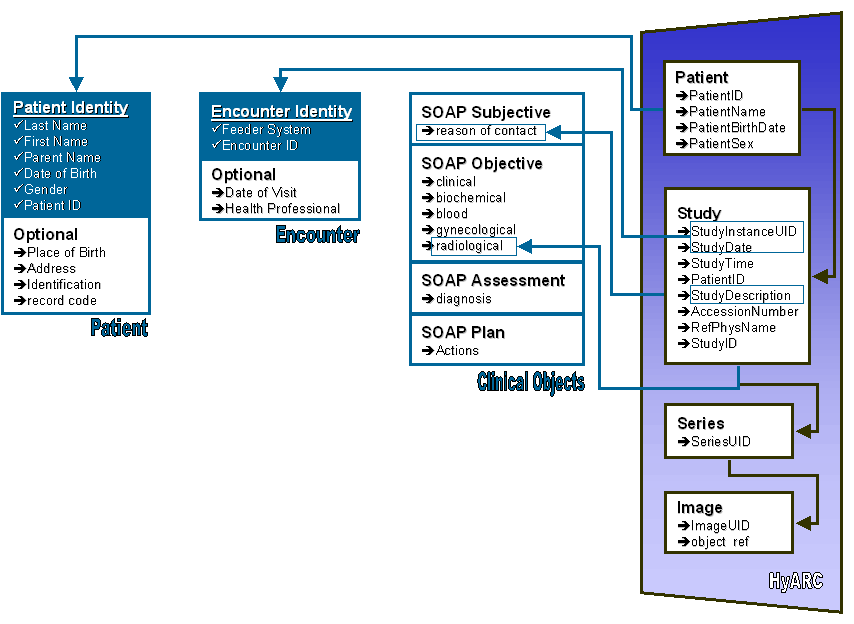
Figure 35: Mapping Of the HyARC Information Model to PCDD.
The PCDD CDES is a limited case of a feeder system. This is an information system that has been designed specifically for entering data into PCDD. If a healthcare organizational unit does not have a specialized clinical information system, the PCDD CDES may play the role of a feeder system.
Since the CDES is considered as a feeder system, there is a SystemType entry with uid=CDES v1.0. In addition, for each CDES installation to a clinic or healthcare facility (i.e. feeder system), a SystemInstallation entry is inserted in the directory.
In the context of the CDES, two different design approaches have been considered: direct and mediated. Both CDES alternatives appear in Figure 36. The direct approach uses the PCDD Update interface to update the directory. Thus, the direct approach follows a similar concept to that of spontaneous updates that has been discussed in the section on periodic on-line updates (4.3.3). The clinical data entry system updates the directory and is a client of the shared workspace for accounting and auditing purposes.
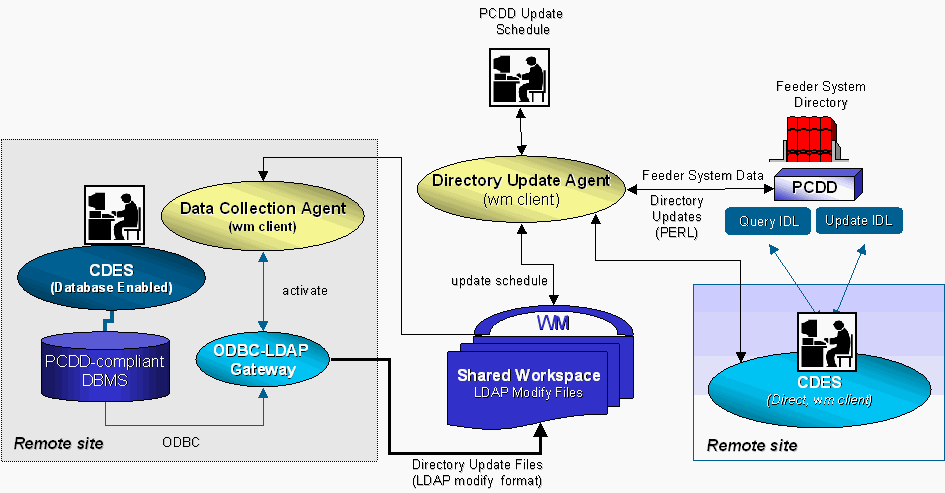
Figure 36: The PCDD CDES May Operate In A Direct (Remote Site On The Right) Or Mediated (Remote Site On The Left) Fashion.
In the mediated case, the CDES operates as an autonomous information system with its own database. The schema of the CDES database corresponds to the schema of the directory. The database stores all updates to the directory that are entered through that specific client. Every time the client wants to query its own EHCR segment, it queries the local database. The data collection agent follows the periodic on-line updates model discussed in section 4.3.3: it activates an ODBC-LDAP gateway which connects to the local database, gets all the data, and translates it to LDAP modify statements.
The objective of the Virtual EHCR service is to deliver an encounter-centered view of the patient's EHCR. It utilizes the PCDD Update interface to provide a consistent way to locate, access and secure information about a patient's EHCR segments. The Virtual EHCR is a front-end to an EHCR indexing service, namely PCDD. PCDD indices both structured and unstructured information that is provided by co-operating information systems, without imposing any constraint on their internal operation or their interface, beyond the medical encounter level.
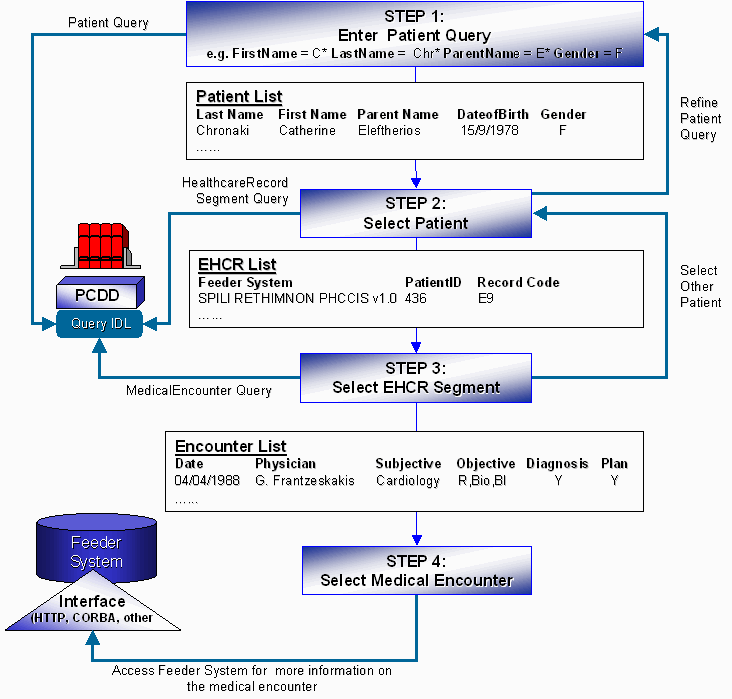
Figure 37: Query Model of the Virtual EHCR Service.
The query model of the Virtual ECHR service appears in Figure 37. To begin with, let’s consider the simple case of the treating physician, who through a web browser, wants to log on into the Virtual EHCR server and request information on a specific patient. The Virtual EHCR provides the treating physician with a summary of a patient’s EHCR segments. From this summary, the physician may request further information on a particular item by clicking on the appropriate link. Patient queries in the Virtual EHCR service are based on the following rules:
Figure 38 displays the entry-point to the Virtual EHCR service.
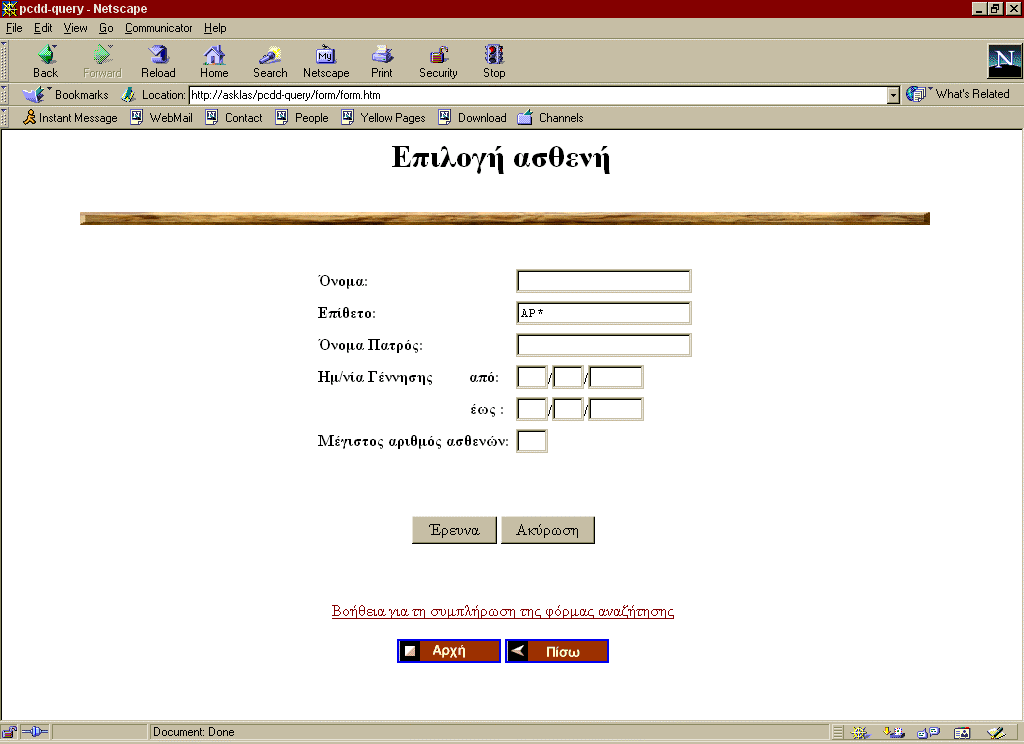
Figure 38: Entry Point to the Virtual EHCR Service.
As it has already been presented in Section 4.1, the PCDD operates on the assumption that a patient’s first and last names, his/ her parent’s name, as well as the personal date of birth identify him/ her uniquely. Patient identification can be initiated by providing some initial query criteria, based on this assumption. Thus, all patients that have the same lastName, firstName, parentName, and birthDate are considered by the Virtual EHCR service as the same. User interaction follows a patient-centered navigation model, which consists of patient query, patient selection, EHCR selection, encounter selection and access to feeder system.
Having entered the patient query criteria at Step 1 of Figure 37 the Virtual EHCR service navigates from the screen of Figure 38 to a screen similar to the one of Figure 39. This is the point where the patient needs to be selected to be uniquely identified.
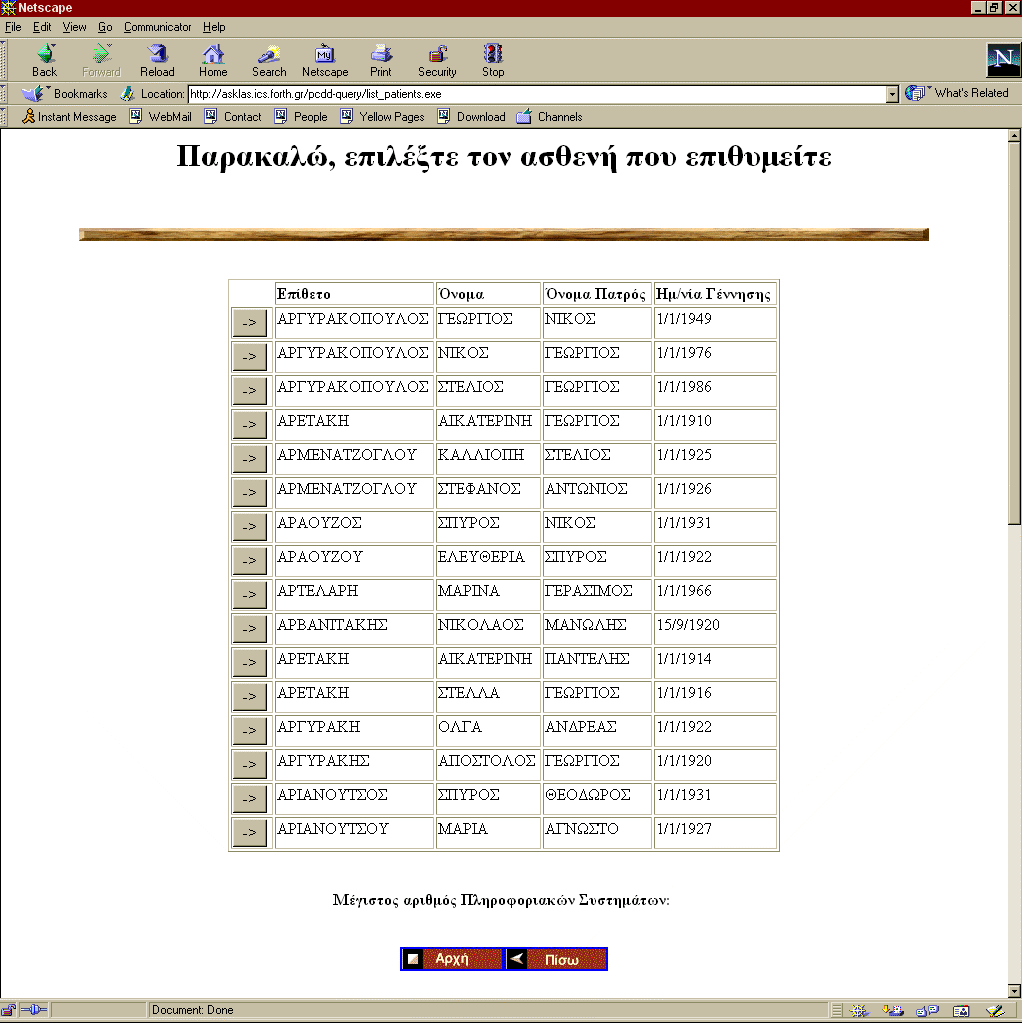
Figure 39: Patient Selection.
After having selected the patient whose clinical information is needed (Step 2 of Figure 37), a screen similar to the one of Figure 40 displays all the patient’s EHCR segments that have been indexed and are available within the PCDD.
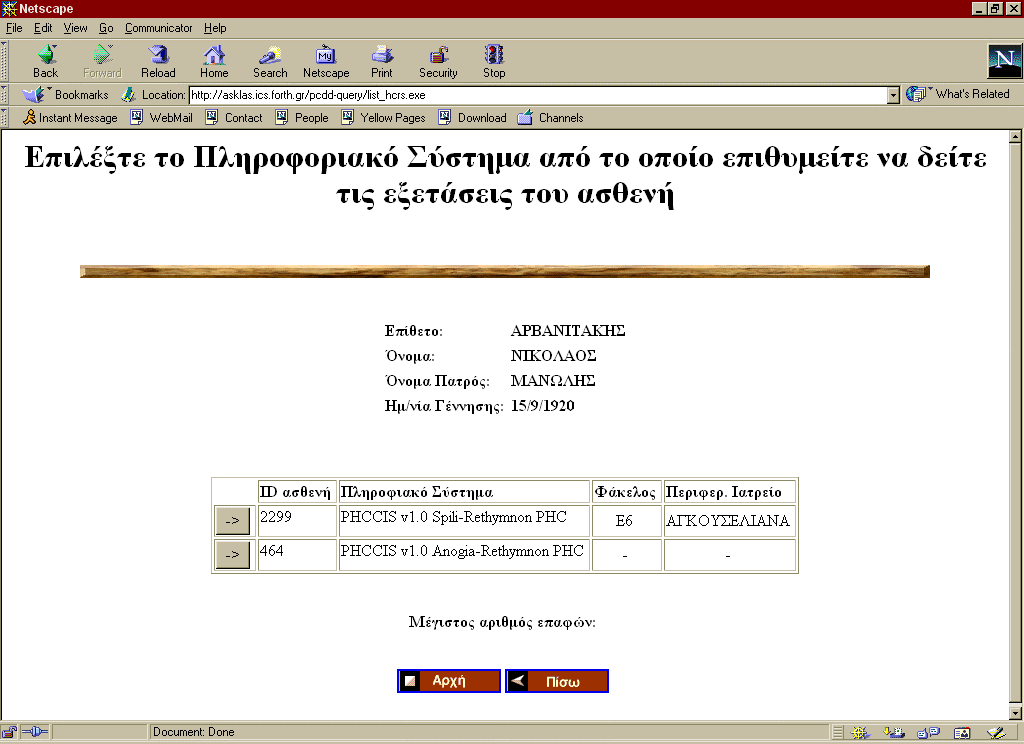
Figure 40: Selection of Patient’s EHCR Segment.
Finally, Figure 41 displays all the medical encounters that have been recorded within the selected EHCR segment that is selected (Step 3 of Figure 37).
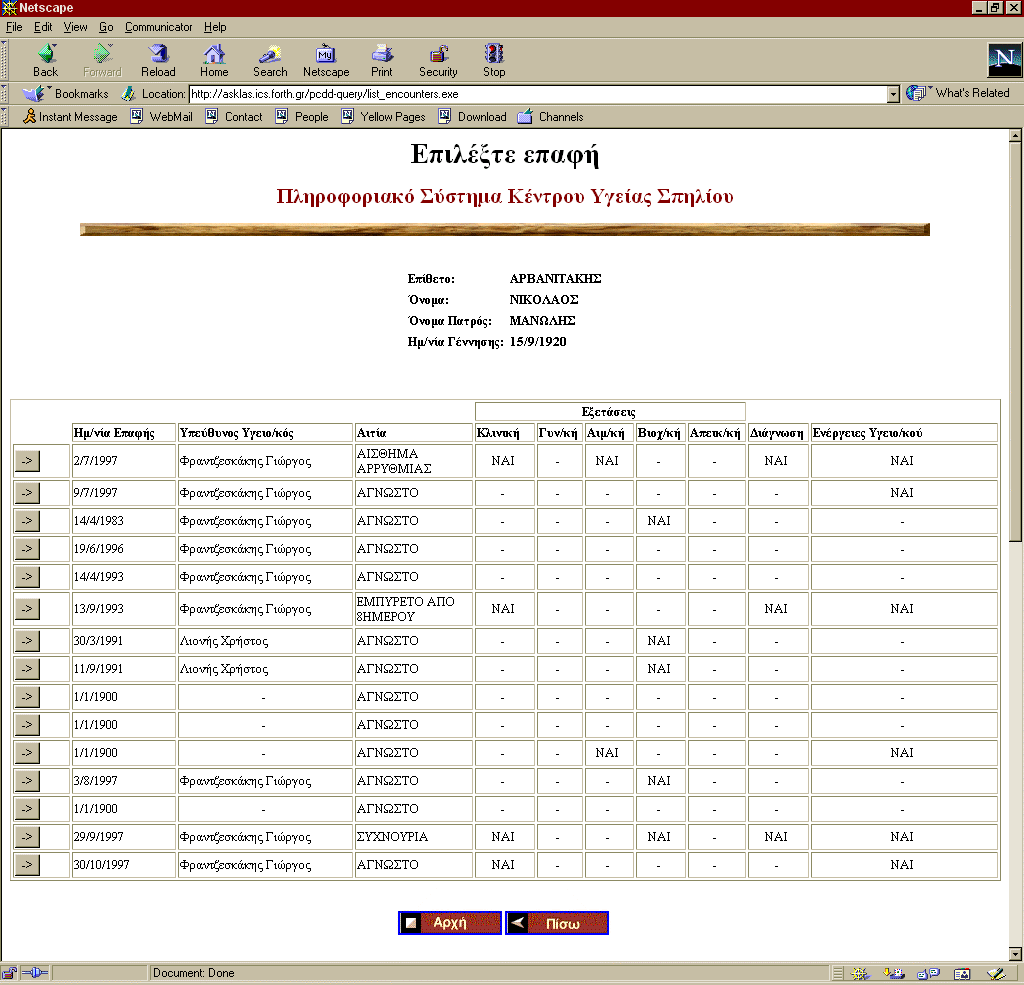
Figure 41: Existing Medical Encounter Information within the PCDD for the Selected Patient’s EHCR.
During step 4 (access to the native interface of feeder systems), the user stops viewing clinical data through the unified user interface. It is up to the authorized human requesting the clinical information, to understand the meaning of the clinical objects on display. In other words, the Virtual EHCR service does not deal with semantic integration and interpretation-related issues. It barely uses the indexing mechanisms of PCDD to search for patients and their EHCR segments inside the PCDD and provides direct access to the clinical objects in feeder systems that are available. Nevertheless, the existence of CORBA-compliant clinical information systems can make possible a unified access mechanism like the one of Figure 42.
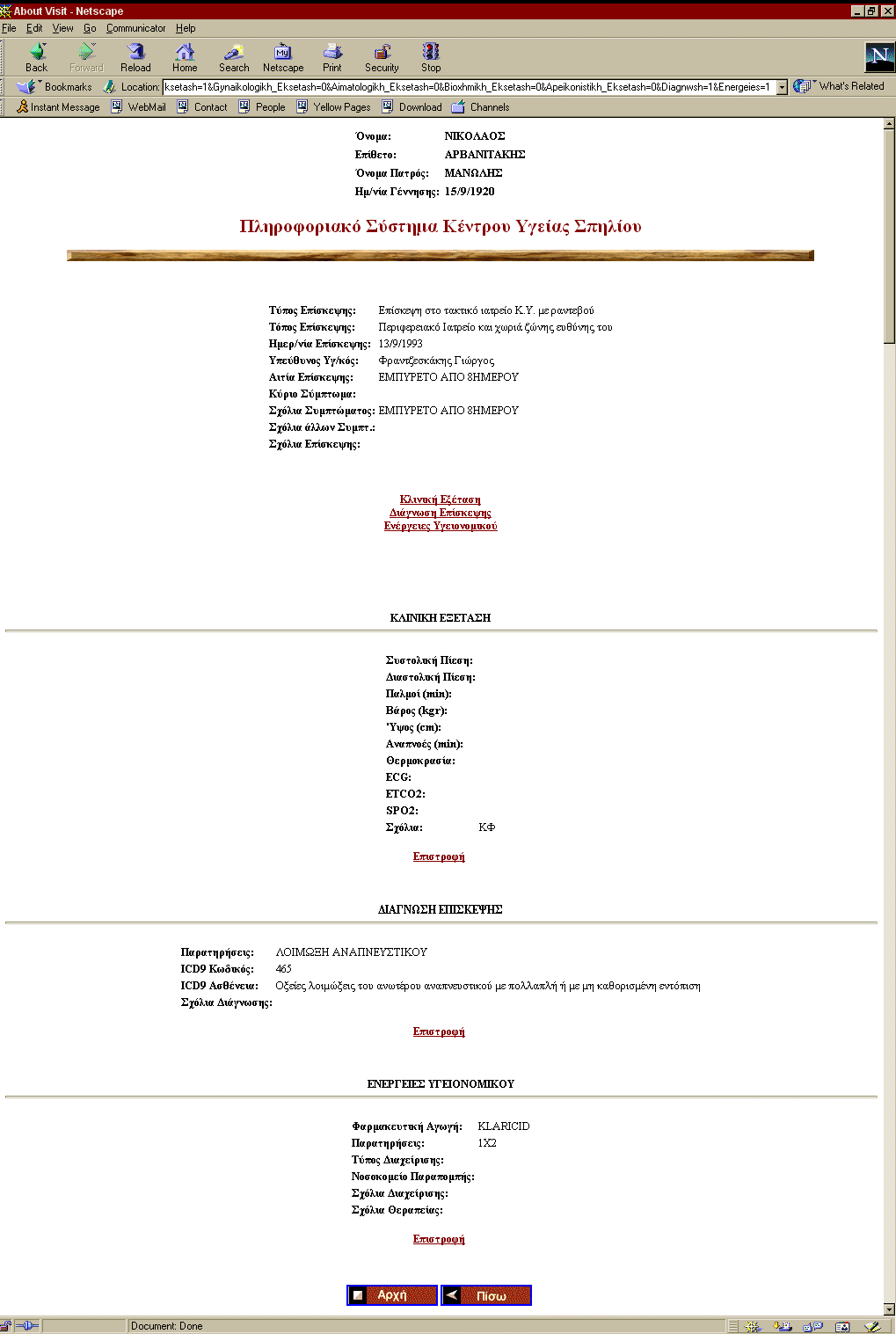
Figure 42. The Unified User Interface For Accessing Clinical Observations, Facilitated By Means Of A COAS-Like CORBA Interface.
The PCDD Monitoring application will provide an environment for the definition of persistent encounter-oriented queries PCDD. Such a query could be "Give me a graphical representation of the frequency vs. time of medical encounters in PCDD for all the feeder systems in the federation." The main idea of the PCDD Monitoring application is to provide the ability to define such queries on the directory and observe the evolution of their results as the directory is extended in depth (clinical objects) and width (feeder systems).
The PCDD Monitoring application is currently on the requirement definition stage. It will be designed on top of the PCDD Statistics interface, which provides access to the data in the PCDD hiding away all patient identification attributes.
One of the major obstacles that had to be overcome in designing PCDD, is the absence of unique patient identification. This is due to the fact that organizations usually assign IDs that uniquely identify patients within their local ID domain of ID values. As a result, these ID values are meaningless outside these particular systems or organizations. OMG’s Person Identification Service (PIDS) [PIDS98] organizes person ID management functionality to meet person identification needs in an environment with multiple naming authorities and identification traits.
In PIDS terms, PCDD is yet another naming authority. Naming authorities are also the clinical information systems in the PCDD federation. In a global infrastructure based on CORBA, PCDD will be interoperable if it provides a PIDS interface. The development of such an interface is part of developing the patient ID correlation service.
The Patient ID correlation service will provide the correlation interface of PIDS on top of PIDS interfaces provided by feeder information systems. The service correlates identifications of a patient in the federation, through his/ her main identification attributes (i.e. lastName, firstName, parentName, birthDate, and gender). Emphasis in this service will be given on the interoperability of PCDD with other global directories that provide PIDS interface. The correlation service will also be useful for maintenance purposes, since the contents of the directory need to be reviewed on regular intervals.
Information technology planners use the term architecture to refer to abstract technical descriptions of systems, which are conceptually based and provide the basic framework for the creation, movement, distribution, use, and management of information [XWIT94]. A reference architecture model describes a system in terms of basic functional elements and the interfaces among them. It clarifies where protocols need to be defined and identifies groups of functionality, without implying a specific physical implementation. The reference architecture for the HII shown in Figure 43, guides the development of a health-telematics network for the provision of integrated services [Tsiknakis97] [Orphanoudakis98a] [Orphanoudakis98b]. It provides a general framework in which medical image databases and other healthcare-related information systems may be integrated to provide media-rich services to healthcare professionals, social workers, and the public. It is important to note that the HII provides a conceptual roadmap, since it does not imposes any execution platform, and consists of a vast conglomeration of autonomous information systems and supporting services.
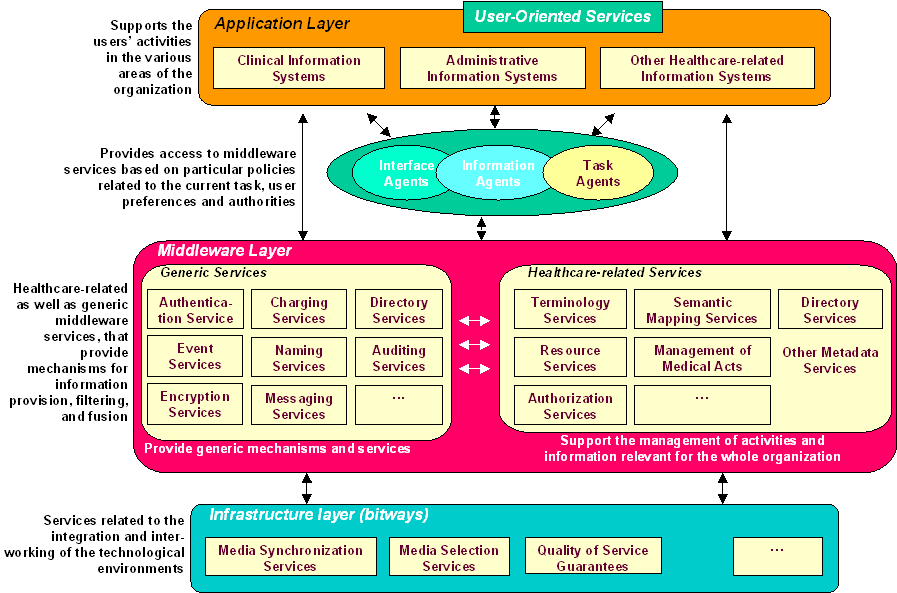
Figure 43: HYGEIAnet Reference Architecture.
Users are primarily interested in information processing applications, which they may own or gain access to as end-users via communications networks. These services are ‘enabled’ by other underlying, transparent services provided by information and network service providers. Applications and enabling services employ certain information processing services and systems for data transport, which may be distributed throughout the existing HII. Thus, the HII consists of three basic components: applications, enabling (or middleware) services, and network infrastructure. At the bottom of Figure 43, the Infrastructure layer provides services that are related to the integration and inter-working of the technological environments. The Application layer, through the User-Oriented Services, supports the users’ activities in the various areas of the organization.
In the Middleware layer of the reference architecture reside generic and healthcare-specific middleware services. Generic middleware services support the applications with general-purpose facilities, which are common to any information system in any type of business domain [CEN/TC25195]. Directory services based on X.500/ LDAP provide white page directories (i.e. information on healthcare professionals), as well as yellow page directories (i.e. information on healthcare facilities and services). Certification services provide certificates to various actors and enable the evolution of a trust infrastructure. Encryption services support secure data-transfer over communication networks. Charging services enable financial transactions, while auditing services facilitate the tracking of access profiles on information objects providing traces of activities concerning their creation, modification, deletion, etc. Naming, indexing, and searching services are essential for the efficient location and retrieval of information objects. Event services support de-coupled communication between information objects through the delivery of event notification messages. Finally, messaging and collaboration services allow the peer-to-peer synchronous and asynchronous communication of information objects based on standard communication protocols.
Healthcare-specific middleware services support applications with services related to activities of the healthcare domain. Regional resource services provide information on the availability of physical resources such as hospital departments, diagnostic modalities, mobile emergency units and their characteristics. Educational resources, such as public health information and access to digital medical libraries, are also enabled by resource services. Access to and use of the medical data maintained by healthcare information systems in different authorization domains, is subject to strict confidentiality policies. The enforcement of these policies necessitates the synergy of healthcare-specific services, such as authorization services, with generic services such as security and certification services. Flexible domain-specific authorization services based on generic security and certification services conform to the evolving legislation regarding telemedicine. Terminology-mapping services map one terminology standard to another. Semantic mapping services provide mediation and translation services that facilitate the mapping of heterogeneous information sources into a global domain model. Management of medical acts enables the coordinated execution of healthcare-related tasks, facilitate functional integration, and coordinate medical procedures in terms of quality, throughput, and reliability [Kaldoudi97] [Katehakis97].
Agent-based technology provides access to generic and healthcare-specific middleware services based on particular policies related to user preferences, tasks, and authorities. Agents in the form of mediators and facilitators have been widely employed as a means of providing assistance to users in the complex tasks of information tracking, filtering, and fusion [Wiederhold96] [Sycara96]. Interface agents interact with the user to receive user specifications and deliver results. They acquire, model, and utilize user preferences to guide system coordination in support of the user’s tasks. Task agents help users perform a task by formulating problem solving plans and carrying out these plans through querying and exchanging information with other agents. Information agents provide intelligent access to a heterogeneous collection of information sources.
Figure 42 places PCDD in the context of the HRA. It uses general terms drawn from the HRA definition to describe the components of the PCDD. Notably, the middleware services involved in the PCDD are both generic and healthcare-specific. The generic components deal with security, auditing, naming, and ORB services. Auditing services are enabled by the WebOnCOLL infrastructure, as described in Section 4.3.3. Translators map data exported from feeder systems to LDAP templates. So far ODBC-LDAP and DICOM-LDAP translators have been considered as data extraction gateways (Section 5). The task agents shown in the figure correspond to directory update agents, which coordinate PCDD updates (Section 4.3.3). The PCDD enables the user-oriented services described in Section 6, namely a Virtual EHCR service, a PCDD Monitoring service, and a Patient ID Correlation service.
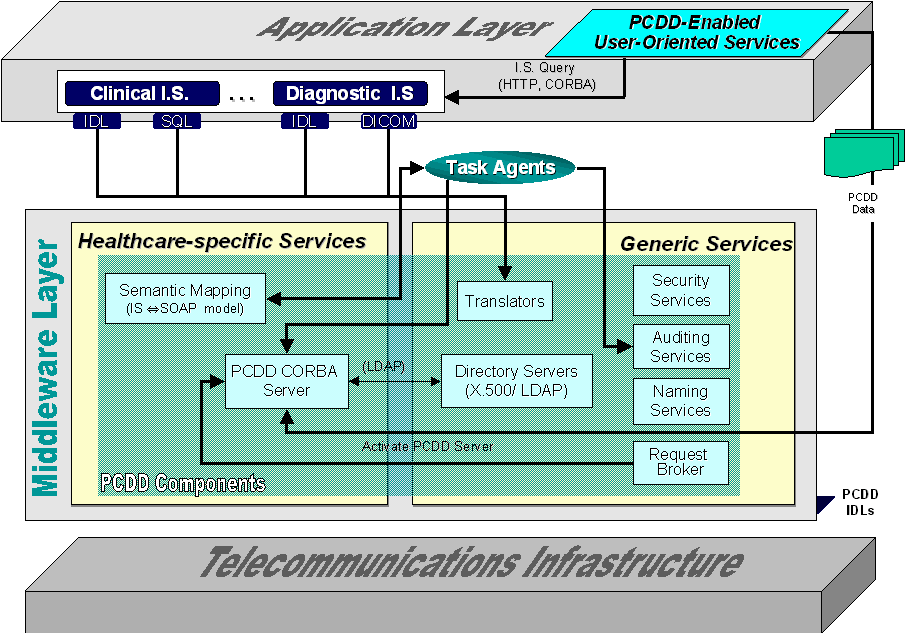
Figure 44: PCDD in the Context of HRA.
Architectural issues related to the presentation of information deal amongst other with user and environment profiles, management and communication, as well as communication with the application core (Figure 45). Any HII should be able to provide integrated support to clinical, organizational, and managerial activities, and in the distant future to offer a single user interface for access to the global healthcare-related information space. The Virtual EHCR, as used in the current context is “virtual” in the sense that it provides a uniform view of data (meta-data) possibly configured to work differently at different locations. Due to the fact that users seek selective information, following specific paths depending on their personal preferences, it is expected that the Virtual EHCR concept will eventually lead to a uniform applications and services environment. Since electronic records can provide much easier navigational facilities, navigational issues will become even more important in the future, mainly because of the end-user requirements to have similar interfaces in terms of look and feel. In addition any such interface should be able to work both on secure and insecure environments. This is the main reason why the existence of cached information is not desirable in any sort of User Interface (UI) implementation.
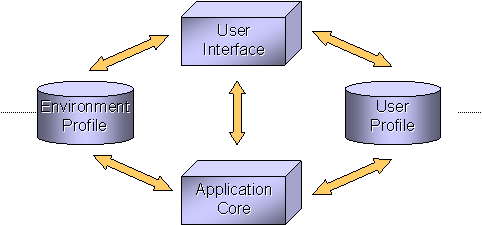
Figure 45: UI General Architecture.
Challenges in the area of human-computer interaction have always focused on the design of UIs accessible by different user groups and the propagation of existing guidelines into user-adaptable user-interface implementations [Stephanidis97b]. This, together with the emergence of Graphical User Interfaces (GUIs) has led to the proliferation of lexical technologies incorporating advanced multimedia interaction facilities, novel input/ output devices and multi-modal interaction techniques [Stephanidis97a]. This has contributed to an ever-increasing number of computer users, characterized by diverse abilities, requirements, and preferences. In addition, context has become more complex and knowledge demanding. The fact that, in the majority of cases, domain experts use computers in a completely different manner than simple users makes necessary the existence of available user profiles. In addition, due to the fact that users do not share the same level of experience, interaction techniques should be suitable for all the range of users including both computer-literate and computer-illiterate.
Awareness of contextual factors is important for the development of appropriate and usable human-computer interfaces. This means that employing a Usability Context Analysis (UCA) [Thomas96] methodology helps collecting specifications on the number and special characteristics end users have, as well as the tasks they need to carry out. The organizational conditions under which users work are very important also, together with the available hardware, software and any network environment that exists. All this information is necessary so that usability measures and criteria are specified prior to any evaluation.
Several levels of security exist; namely information system security, operating system security, database system security, network security, communication security, etc. The presented approach does not face security isolated in a per-process (or use-case) point of view. Instead it follows a two level approach that can guarantee greater availability, integrity, and confidentiality. The first level of security is implemented by means of the HYGEIAnet Virtual Private Network (VPN) that offers Committed Information Rate (CIR) for medical applications and is suitable for both auditing and statistics. This security level increases service availability and can implement restrictions on virtual servers and directories. In addition, since the HYGEIAnet VPN is connected to the Internet by means of firewalls, it is capable of controlling both incoming and outgoing traffic by means of IP address grant/ deny restrictions. Both inside the VPN, as well as at any end-to-end point connection a "Secure Tunnel across the Internet" approach is followed. This second security level approach can guarantee secure communications through insecure channels by means of encrypted and authenticated communications, and can be applied not only inside firewalls but also to every computer. This way it can guarantee secure connections for both remote users and among sites.
X.509 [ITU93b] is the ISO standard for digital signatures and ensures secure and authenticated communication. Each person in the white page directory may own a "digital signature," which allows him/ her to sign documents and messages transmitted electronically. Access to the directory also allows other users to access a public key associated with an individual listed in the directory. Encrypting a message with a public key ensures that solely the holder of the corresponding private key may read the message. A certificate server can publish certificates and certificate-revocation lists to directory servers using the LDAP web directory protocol for easy distribution to clients and servers. Certificate management operations can be performed remotely using familiar protocols such as SSL [Freier96], HTTP-S, and HTML. Clients request certificates by filling out customizable HTML forms, and they receive them via HTTP. Servers request and receive certificates via email. This way support for open standards can be achieved and provide end users with confidence that they will be able to communicate within heterogeneous computing environments.
For the PCDD to be able to offer secure services it needs to be able (a) to authenticate each client’s principal identity, role and sensitivity, and (b) to transmit information confidentially and with integrity. It is evident that the existence of a trust infrastructure [Chu97] needs to evolve as part of the HYGEIAnet. This way security and confidentiality services can be based on a regional certification authority, which will provide digital certificates to healthcare facilities and human resources. The purpose of the certification authority is to certify the role and authority of both users, and services (or applications) within the regional healthcare network. The combination of digital signatures for authentication, public key cryptography for recipient authentication, and Secure Socket Layer (SSL) protocols for secure data-transfer, provide the necessary technological framework for secure communication of healthcare related information across the Internet.
Access control is achieved by means of user profile information. In this context any patient should be able to have complete access to all personal information. A physician should have access to all information that has been provided by him, as well as to his/ her referral data. In addition patients should be able to grant and restrict access to their personal information. Of course this may lead to very tight security constraints that is capable of making ineffective the use of healthcare information systems. Hence more emphasis needs to be paid on auditing "who accesses what type of information at what time," instead of trying to enforce very tight security constraints.
The concept of the Patient Meta-Record (PMR) has been introduced in [Orphanoudakis95] to turn a large, heterogeneous and distributed set of Computerized Patient Record (CPR) components into a seemingly integrated and homogeneous healthcare record. The PMR concept permits the integration of EHCR segments, and also provides aggregation and navigation facilities (which, in turn, can be fully configured and customized) in order to assist in the appropriately personalized utilization of the EHCR by the respective functional units or Healthcare providers [Tsiknakis96]. The PMR manages, at a single logical point, references to all of the physical information related to a patient throughout the Integrated Hospital regardless of where such information may reside. Therefore, among all the PMR is an indexing system, providing access to all stored data for a particular patient. The PCDD is a HII middleware that provides a realistic approach to the vision described in these papers. It utilizes a distributed directory infrastructure and a simple model of information integration that facilitates extensibility in terms of information sources.
On the other hand, the Patient Meta Record (PMR) utilizes naming, directory services, and the HRDM to deliver a semantically consistent view of the geographically distributed healthcare record segments [Leisch97]. The PMR is associated with SIS [Constantop95], a network database that contains meta-information about the attached healthcare information systems, as well as workflow information such as information about clinical procedures. The use of the PMR as a middleware service is threefold; it facilitates semantic mapping between heterogeneous information systems; it can facilitate semantic queries; it can be used as an information source for the workflow management of applications. The goal of the PMR is to provide semantically consistent data model of the clinical objects residing in diverse healthcare information systems. The PMR approach is driven by a semantically rich model (HRDM) to which the models of all clinical information systems are mapped. Thus, it is mainly a top-down approach, conceptually different from the bottom-up approach represented by PCDD. The latter is based on a semantically simple approach that places emphasis on the indexing of EHCR segments based on general and common notions, as that of the medical encounter. Even though, the PMR approach offers potentially greater information coverage of specific information sources, the associated complexity is significant. In contrast, the only clinical objects of interest to the PCDD are those that correspond to the notion of a medical encounter, a single contact of a patient with a healthcare facility. The semantic interpretation of clinical objects that are returned from a feeder system once more information is requested on particular “encounter,” may be enabled by global or dedicated semantic mapping services. Thus, semantic mapping is orthogonal to the PCDD middleware. In this sense, the semantic work in the context of the HRDM [Petru97] can blend well with to the work of PCDD. Note however that in the PCDD approach, semantic mapping of the clinical objects provided by feeder system, can be provided incrementally on a need-to-know basis, a fact that allows fast deployment and early feedback.
The objective of the Synapses Project [Synapses97a] [Synapses97b] is to facilitate the sharing of health records among information system consistently, simply, and securely. The approach that has been followed is that of middleware servers that enable healthcare professionals to access information from feeder systems. The Synapses Federated Healthcare Record (SynFHCR) provides a harmonized view of the healthcare record drawn from feeder systems, and is realized through a series of specific responses to formal requests for Synapses objects, i.e. record components which are in the simplest form clinical data sets. The information model of these clinical objects is encapsulated in the Synapses Object Model (SynOM), which facilitates a standardized record exchange format. The actual middleware that realizes the Synapses federation is the Synapses object dictionary, which includes a dictionary set together with a set of access methods. Users use terms in the dictionary to define potential record extracts, and the access methods to get them. Besides including terms, the dictionary enables the cross-referencing of the terms in feeder systems. The Synapses approach bares some similarity with the PMR approach in that in its deployment it involves the definition of basic query types and the clinical constructs they may involve. Associated access methods facilitate the extraction of these clinical objects from feeder systems. Note, however, that the deployment cost of such a solution is really high. Based on a personal communication with a member of the Synapses project, the introduction of a single system into the model took about a year.
The STARP project [Blazadonakis97] identified a set of core services that are used by a range of user services i.e. multimedia patient dossier, telemedicine, as well as control and management of healthcare resources. These core services are the Patient Reference Manager, the Regional Enterprise Manager, the Security Server, the Public Key Manager, the Local Enterprise Manager, the Act Manager, the Patient Dossier Manager, and the Booking Server. Core services care classified into regional services that are delivered by regional center, and local services that are delivered by each healthcare organization. PCDD corresponds to the Regional Patient Reference Manager (RPMR) which provides patient identification information facilities as well as information on contacts that patient have had in one or more healthcare organizations. Although the STARP approach is conceptually close to PCDD, there is a number of differences. The star approach is entirely web-based. Each healthcare organization and regional center is supported by a web infrastructure (i.e.web server, security server). RPMR updates are spontaneous. A patient exists in the RPMR if a healthcare professional published a patient reference to the RPMR, probably in the course of a referral. In contrast, PCDD is updated mainly through periodic on-line “bulk” updates. Also, in STARP approach the information on a patient’s contacts (medical encounters) are organized in “episodes of care,” which are active (i.e. they have a state). The current version of the PCDD is not active and does not support the notion of an “episode of care.” Finally, as far as we know, the implementation of the RPMR it does not support an LDAP interface and does not offer the potential for distribution and shadowing offered by directory technology.
The Record Locator Service [Star98] provides location services on the distributed segments of a patient EHCR. As such, its information model is simpler than that of the PCDD. Note, however, that the additional effort that is required to support encounter information as in PCDD is not significant. On the other hand, the RLS may be used in combination with multiple information models for the indexing of EHCR segments.
GEHR provides a specification for an exchange format [GEHR95], and supports the idea of systems exchanging healthcare data in a standard exchange format. Thus, GEHR does not support the idea of a “Virtual EHCR.” Lately, the advance of XML has swept away the GEHR approach. According to the XML approach, different systems exchange data using documented Document Type Definitions (DTDs). These DTD are standardized for different clinical objects. XML stands between SGML and HTML and allows the viewing of medical data in a unified user interface provided by an XML viewer. PCDD is largely viewed as an enabling service for the Virtual EHCR. As such, its objective is different from that of GEHR whose goal is to mitigate differences in the model of different clinical information systems.
The Distributed Healthcare Environment (DHE) takes a rather process-oriented approach in the delivery of health services [Ferrara98]. The PCDD is certainly a technology that can be utilized within DHE framework.
The ARTEMIS project aims to ‘advance cooperative activities of health care providers to promote the delivery of total and real-time care’ [Pargaonker95]. A multidisciplinary group is involved in the development of a web-based collaboration environment for the healthcare domain. In this environment, physicians treat patients using healthcare records and knowledge, such as cost information and research findings, originating from distributed sources. Furthermore, community-care networks of primary and specialized care providers collaborate to meet the healthcare needs of the community. ARTEMIS is currently used in daily practice. The ARTEMIS approach exploits the effectiveness of open standards like HL7 and CORBA. It does not, however, employ a notion of a directory as PCDD does.
In the TeleMed project [Kilman97], the virtual patient record forms the basis for a CORBA-based collaboration environment in which multiple physicians, and ultimately the patient, can engage in interactive electronic discussions. Multiple physicians at remote locations can simultaneously view, edit, and annotate multimedia patient data. Each physician can see the data another physician has entered as well as monitor some of the other physician’s interactions with various user interface windows. In this way, TeleMed may be used to support referral and teleconsultation sessions. The relevant technology will soon be introduced into daily practice, in a community network. TeleMed employs CORBA technology and it offers a PIDS interface for patient identification in the different sites that it has been installed. A PIDS interface is within the future plans of the PCDD project.
It is evident that a number of projects around the world address the problem of locating, indexing, and accessing the distributed segments of a patient's EHCR. The level of integration supported by each of these efforts varies, and so is the complexity of the effort. In essence, there is a trade-off between the diversity of clinical objects stored in the directory and the generality and expressiveness of the model. The more information you place in the directory, the richer query model you may support. This, however, limits the range of clinical information systems you may incorporate in a non-trivial way. Furthermore, PCDD becomes heavier and harder to maintain. This trade-off is shown in Figure 46, which shows an estimate of the implementation effort required to achieve information integration, in the case where patient and feeder system are registered in the directory, the PCDD case, and the case where arbitrary clinical objects are included in the directory.
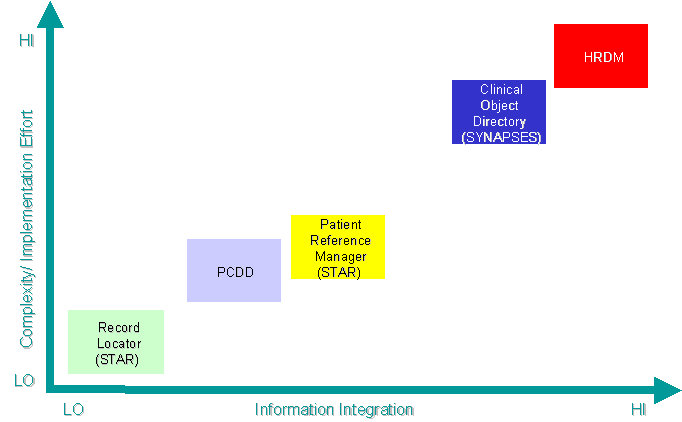
Figure 46: Estimated Information Integration vs. Complexity/ Implementation Effort in Different Approaches to the Virtual EHCR Problem.
According to [Paepcke98] the most important criteria for evaluating interoperability solutions have to deal with component autonomy, entry infrastructure cost, ease of contributing and using components, breadth of task complexity, and scalability in the number of components. The presented approach utilizes the existing HII of the regional healthcare network of Crete, providing enough component autonomy without leading to solutions that require very expensive component descriptions or translation facilities construction. The learning curve for facilitating remote access and visualization of distributed EHCR segments once climbed, it promises to deliver industrial strength results that can provide information services for everyday use. Since this approach involves complex, and in many cases incompatible, structures and multiple component methods, a CORBA-like approach is much easier to use, because it takes care of packaging parameters appropriately for travel over the communication link and syntactically allows components to be viewed as if they were local objects.
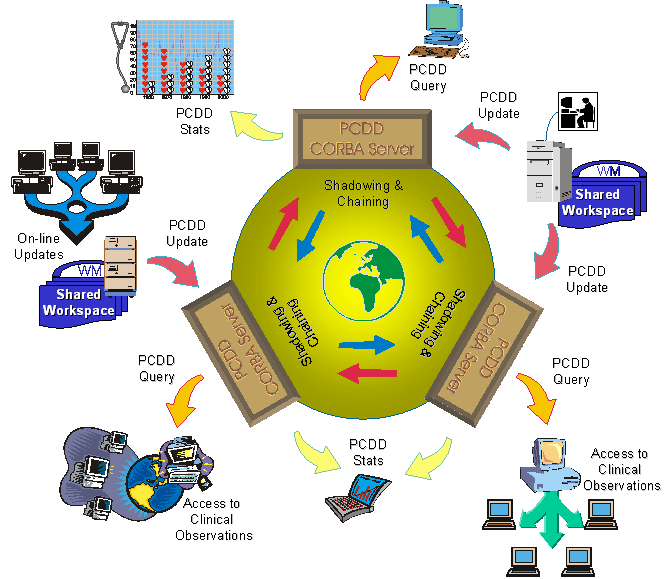
Figure 47: The Introduction Of Shadowing And Chaining Mechanisms Provides An Extremely Scalable Solution To The Problem Of Indexing (And Thus Accessing) Of Clinical Multimedia Data.
The PCDD indexing system is a middleware that can provide access to clinical information throughout the distributed EHCR segments maintained by autonomous information systems in a regional health-telematics network such as HYGEIAnet. The PCDD maintains a distributed registry of feeder systems, patient key demographics, medical encounters and references to clinical objects. The technological approach that has been followed in the implementation of the Virtual EHCR service uses a series of Java applets and cgi-scripts, which interact with a PCDD server using the IIOP protocol. In addition, the nature of the directory infrastructure is inherently distributed. Thus, there may exist multiple directory servers, interconnected through shadowing (back up) and chaining (referral) and multiple CORBA servers offering the PCDD Query interface. In such a case, the Virtual EHCR service connects to a "nearby" CORBA server and all information received will usually appear as if it came directly from that server. From the user's point of view, the Virtual EHCR service behaves exactly as if the end users were accessing a centralized server. The PCDD query service provides a unified interface to the user, regardless of the physical location of the information accessed. This extremely scalable architecture is depicted on Figure 47. Feeder systems (clinical information systems) support diverse access methods ranging from human-mediated, to CORBA object references, and HTTP URLs. Responding to the need for consistency and accuracy, service quality in PCDD is based on scheduled periodic on-line updates that can be facilitated by the existing WebOnCOLL infrastructure [Chronaki97] [Chronaki98a].
There are several reasons for not replicating the clinical objects in the directory. First, there is a number of medico-legal issues that are still open (e.g. who is the owner of clinical data, who has the right to access what kind of data, in what way the results are to be used, etc.). Second, keeping the directory model general increases the accuracy of its contents and maximizes its extensibility in terms of feeder systems. Furthermore, information is kept close to the people or processes that make the heaviest use of it, or are responsible for keeping it up to date. Finally, reducing the size of the directory makes it easier to cache, replicate, and in general, manage. This goes back to the main objective of PCDD, which is to provide maximum information coverage in terms of feeder systems in the federation, possibly sacrificing depth in terms of semantic coverage.
The lack of a standardized interface for accessing clinical objects has forced the current implementation to follow an open architecture approach that utilizes the best available technologies for accessing clinical multimedia data. It is indeed a fact that information systems use different technologies and terms for accessing the same clinical objects. CORBAmed currently leads the definition of interoperable specification effort that can support activities related to accessing directly a greater variety of healthcare information. CORBAmed’s interoperability specifications, such as PIDS, COAS, CIAS, LQS, and HDIF can provide the generic interface framework for accessing clinical information systems. They can also facilitate the extraction of regional healthcare indicators throughout HYGEIAnet. These indicators can be monitored, and traced in time by means of appropriate environment profiles.
Another important aspect of information integration, is the provision for semantically consistent data during the request and retrieval of clinical objects from EHCR segments. This requires the existence of an authority service or a terminology server [Rector93] [Rector94], which checks or suggests the medical terms used by feeder clinical information systems to enable them to communicate information elements unambiguously to the target. It needs to be investigated, how such an existing service can be incorporated into the framework. One such solution could be the use of OMG’s Lexicon Query Service (LQS) [LQS98] as a mediation service, facilitated by means of HRDM [Petru 97]. Future work could also include the extension of the PCDD semantics to include information regarding the state of medical encounters. This extension will increase the level of information integration in the directory at the cost of a more complex directory structure. Nevertheless, this should not contradict with the design effort put on using the minimum possible set of semantics. This way, PCDD is capable of supporting federations of healthcare information systems by offering maximum autonomy to the individual clinical information systems and minimum transition effort for the involved migration teams, minimizing thus the possibility of mistakes during semantic mapping.
In regard to security, smart cards could be used for distributing private keys both to physicians and patients. These smart cards could be used in conjunction with a Personal Identification Numbers (PIN) to allow building the trust infrastructure of HYGEIAnet. Certain business rules still remain to be identified, classified, and deployed. The exact implementation approach still needs to be investigated in more detail. At present more emphasis should be paid on the emerging need for recording auditing information, so that persons who access patient data can be traced. This could be handled by means of the WebOnCOLL’s virtual workspaces that, among other are capable of maintaining session information, history of interaction, and access privileges. All users connected to such a shared workspace can be notified of workspace updates as they occur and may inspect the attributes of workspace objects. Furthermore, a user connected to a workspace may be aware of all other users connected to the same workspace, at the same time.
Potential benefits of advanced health-telematics services such as the ones enabled by the PCDD include among other improved access to medical knowledge and expertise, a reduction in healthcare costs, reduced isolation for both patients and medical personnel, which all lead to improved quality of care. The above benefits will become evident after a transition period, during which users of telemedicine services receive proper training and learn to trust them, potential legal issues are resolved, and capital and operational costs are reduced, while service quality is improved with new technological developments.
The work presented in this report is the result of the collaboration effort of a large group of people within CMI-HTA, ICS-FORTH that have worked on this topic on and off for over a year now. The core of this group was Dimitrios Katehakis, Catherine Chronaki, and Stavros Kostomanolakis. Detailed contributions are outlined below.
[ANSI97] ANSI/ NISO/ ISO 23950 “Information Retrieval-Z39.50: Application Service Definition and Protocol Specification”, National Information Standards, 1997 (http://lcweb.loc.gov/z3950/agency/document.html).
[Asokan97] N. Asokan, P. A. Janson, M. Steiner, M. Waidner, “The State of the Art in Electronic Payment Systems”, IEEE Computer Magazine, Vol. 30, No. 9, pp. 28-35, September 1997.
[Bainbridge96] M. Bainbridge, P. Salmon, A. Rappaport, G. Hayes, J. Williams, S. Teasdale, “The Problem Oriented Medical Record - just a little more structure to help the world go round?”, Proceedings of the 1996 Annual Conference of PHCSG, Downing College, Cambridge, UK, September 1996 (http://www.ncl.ac.uk/~nphcare/PHCSG/conference/camb96/mikey.htm ).
[Blazadonakis97] M. Blazadonakis, V. Moustakis, and G. Charissis, "Seamless Care in the Health Region of Crete: The Star Case Study", MIE'97, pp. 157-161, Porto Carras, Greece, May 25-29, 1997 (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/papers.html).
[CEN/TC25195] CEN/TC251/WG1/PT1-013, “Medical Informatics: Healthcare Information System Architecture.” Brussels, CEN, November 1995.
[Chronaki97] C. Chronaki, D. G. Katehakis, X. Zabulis, M. Tsiknakis, S. C. Orphanoudakis: WebOnCOLL:Medical Collaboration in Regional Healthcare Networks, IEEE Transactions on Information Technology in Biomedicine, Vol. 1, No. 4, pp. 257-269, December 1997, (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/ieee97weboncoll/ieee97weboncoll.html).
[Chronaki98a] C. Chronaki, D. G. Katehakis, M. Tsiknakis, S. C. Orphanoudakis, “WebOnCOLL: An Open Platform Enabling Collaborative Information Sharing and Its Application in Medicine”. Euro-MED NET'98, Nicosia, Cyprus, March 4-7, 1998, (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/euromednet98/euromednet98.html)
[Chronaki98b] C. E. Chronaki, X. Zabulis, D. G. Katehakis, A. Giannopoulos, N. Stathiakis, M. Tsiknakis, P. J. Lees, E. N. Simantirakis, P. E. Vardas and S. C. Orphanoudakis, “WebOnCOLL Enabled Remote Cardiology Consultation for Suspected Myocardial Infarction”, accepted for an Oral Presentation at MEDNET98.
[Chu97] Y.-H. Chu, J. Feigenbaum, B. LaMacchia, P. Resnick, and M. Strauss “REFEREE: Trust Management for Web Applications”. In Proceedings of the Sixth International World Wide Web Conference, 1997 (http://www.w3.org/PICS/TrustMgt/doc/referee-WWW6.html).
[CIAS98] Object Management Group, “Clinical Image Access Service (CIAS)”, Request For Proposals, OMG Document: corbamed/98-06-17.
[Connoly97] D. Connolly. “XML: Principles, Tools, and Techniques” World Wide Web Journal: vol. 2, Issue 4, Fall 1997.
[Constantop95] P. Constantopoulos and M. Doerr, “The Semantic Indexing System. Technical Report”, Institute of Computer Science, FORTH, Heraklion, Crete, Greece, 1995.
[CORBAmed] CORBAmed Health Care Domain Task Force of the Object Management Group (http://www.omg/org/corbamed ).
[Creamer95] J. Creamer, et al. “The ODBC Solution: Open Database Connectivity in Distributed Environments”, McGraw Hill Text, February 1, 1995, ISBN: 0079118801.
[CybTelemedOffice] Cyberspace Telemedical Office (http://www.telemedical.com).
[DICOM] DICOM: An Introduction to the Standard (http://www.xray.hmc.psu.edu/dicom/dicom_intro/DICOMIntro.html).
[Dilts91] D. M. Dilts and W. Wu, “Using Knowledge-Based Technology to Integrate CIM Databases”, IEEE Expert, Vol. 3, No. 2, pp. 237-245, June 1991.
[Dombal91] F. T. de Dombal, V. Dallos, W. A. F. McAdam, “Can computer aided teaching packages improve clinical care in patients with acute abdominal pain?”, BMJ, 302, 1495-1497, 1991.
[EC96] European Commission. “EDIFACT: Message Implementation Guidelines”, Bernan Assoc., Publication date: December 1996.
[Ferrara98] F. M. Ferrara. "The CEN 'Healthcare Information Systems Architecture' standard and the DHE middleware: A practical approach to the integration and evolution of healthcare systems", Technical Report, DHE project, GESI, Italy, http://www.gesi.it/DHE/DHE_Pdf.htm
[Foody97] M. Foody, “Getting COM and CORBA talking to each other requires more than just lip service”, BYTE Magazine, April 1997 (http://www.byte.com/art/9704/sec8/art2.htm ).
[Forsland97] D. Forsland, “The Role of CORBA in enabling Telemedicine”, in Proceedings of the Global Forum III in Telemedicine, Vienna, Virginia, March 1997.
[Fowler98] M. Fowler, K. Scott, “UML Distilled: Applying the Standard Object Modeling Language”, Addison-Wesley, 1998.
[Frank95] M. Frank, “Database and the Internet”, DBMS Magazine, Vol. 8, No. 13, page 44, December 1995 (http://www.dbmsmag.com/f19512.html ).
[Freier96] A.O. Freier, P. Karlton, and P.C. Kocher. “The SSL Protocol Version 3.0” Internet Draft, March 1996.
[GEHR95] Good European Health Record Project (EC AIM GEHR A2014), “GEHR Architecture”, deliverables 19, 20, 24, 30.6.95.
[HL7Standards] Health-Level 7 Standards (http://www.mcis.duke.edu/standards/HL7/hl7.htm).
[isode] isode, “Why Deploy an Enterprise Directory”, Messaging and Directory Server Products White Paper (http://www.isode.com/IC-6083.html ).
[Jagannathan95] V. Jagannathan, Y. Reddy, K. Srinivas, R. Karinthi, R. Shank, S. Reddy, G. Almasi, T. Davis, S. Qiu, S. Friedman, B. Merkin, and M. Kilkenny, “An Overview of the CERC ARTEMIS project”, Technical Report CERC-TR-RN-95-002, Concurrent Engineering Research Center, West Virginia University, April 1995.
[Katehakis97] D. G. Katehakis, M. Tsiknakis, A. Armaganidis, and S. C. Orphanoudakis, “Functional and Control Integration of an ICU, LIS and PACS Information System”. MIE'97, Porto Carras, Greece, pp. 15-19, May 25-29, 1997, (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/mie97icu/mie97icu.html).
[Kille96] S. Kille, “LDAP and X.500”, Messaging Magazine, September 1996.
[Kim96] P. C. Kim, “A Taxonomy on the Architecture of Database Gateways for the Web”, Database Laboratory, Dept. of Information Communications Engineering, Chungnam National University, Seoul, Korea, July 1996 (http://grigg.chungnam.ac.kr/projects/UniWeb/documents/taxonomy/text.html ).
[Leisch97] E. Leisch, S. Sartzetakis, M. Tsiknakis, and S. C. Orphanoudakis, "A Framework for the Integration of Distributed Autonomous Healthcare Information Systems", Medical Informatics, Special Issue, vol. 22(4), 325-335, 1997 (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/mi97int/mi97int.html).
[LQS98] 3M Health Information Systems, and Protocol Systems, Inc., “Lexicon Query Service RFP Response”, Revised Submission, OMG TC Document CORBAmed/98-03-22, March, 1998.
[Microsoft96] Microsoft Corporation, “DCOM Technical Overview”, PDC ’97 Conference Paper, White Paper, 1996.
[OMG] The Object Management Group (http://www.omg.org).
[OrbixWeb97] IONA Technologies, “OrbixWeba Programmer’s Guide”, IONA Technologies PLC, November 1997.
[Orfali97] R. Orfali, D. Harkey, and J. Edwards, “The Web is in trouble. CORBA and Java are out to save it”, BYTE Magazine, October 1997 (http://www.byte.com/art/9710/sec6/art3.htm ).
[Orphanoudakis95] S. C. Orphanoudakis, M. Tsiknakis, C. Chronaki, S. Kostomanolakis, M. Zikos, Y. Tsamardinos, "Development of an Integrated Image Management and Communication System on Crete", Proceedings of the CAR '95, Berlin, June 1995, pp. 481-487 (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/car95/car95.html ).
[Orphanoudakis98a] S.C. Orphanoudakis, C.E. Chronaki, M. Tsiknakis, and S. Kostomanolakis. "Telematics in Healthcare", Chapter 10, In "Biomedical Image Databases," Biomedical Image Databases, S. Wong (editor), Sharon Fletcher, Kluwer Academic Publishers, 101 Philip Drive, Assinippi Park, Norwell, Ma 02061
[Orphanoudakis98b] S. C. Orphanoudakis, "Integrated Telemedicine Networks and Added-Value Services", Proc. VIII Mediterranean Conference on Medical and Biological Engineering and Computing (MEDICON'98), Lemesos, Cyprus, June 14-17, 1998 (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/medicon98/medicon98.html).
[Pargaonker95] D.V. Pargaonker, V. Jagannathan, Y. Al-Salqan, and T. Davis. “Intelligent Agents, HL7 and Patient Record Databases.” Technical Report CERC-TR-RN-95-003, Concurrent Engineering Research Center, West Virginia University, 1995.
[Panurach96] P. Panurach, “Money in Electronic Commerce: Digital Cash, Electronic Fund Transfer, and Ecash”, Communications of the ACM, Vol. 39, No. 6, pp. 45-50, June 1996.
[PIDS98] 2AB, Care Data Systems, Inc., CareFlow|Net, Inc., HBO & Company, HealthMagic, Inc., HUBlink, Inc., IDX Systems Corporation, IONA Technologies PLC, Oacis Healthcare Systems, Protocol Systems, Inc., Sholink Corporation, “Person Identification Service (PIDS)”, OMG CORBAmed DTF Adopted Submission, OMG TC Document corbamed/98-02-29, February 1998.
[Quatrani98] T. Quatrani, “Visual Modeling with Rational Rose and UML”, Addison-Wesley 1998.
[Rector93] A. L. Rector, W. A. Nowlan, S. Kay, C. A. Goble, T. J. Howkins, “A Framework for Modelling the Electronic Medical Record”, Methods of Information in Medicine, Vol. 32, No. 2, pp. 109-119, 1993.
[Renshaw98] D. S. Renshaw, “JavaBeans, Java's component architecture, is far more than just a collection of components for the client”, BYTE Magazine, February 1998.
[Resnick96] R. I. Resnick, “Bringing Distributed Objects to the World Wide Web”, 1996 (http://www.interlog.com/~resnick/javacorb.html).
[Saliez98] E. Saliez, “Patient Data Locator white paper version 3”, distributed on the Helsinki CORBAmed meeting, July 1998.
[Shuh97] B. Shuh, “Directories and X.500: An Introduction”, Network Notes #45, ISSN 1201-4338, Information Technology Services, National Library of Canada, March 1997 (http://www.nlc-bnc.ca/pubs/netnotes/notes45.htm).
[Siegel96] J. Siegel. “CORBA Fundamentals and Programming” New York: John Wiley & Sons, 1996.
[Srinivasan97] S. Srinivasan, “Advanced Perl Programming (Nutshell Handbook)”, O'Reilly & Associates, ISBN 1565922204 , August 1997.
[Star98] Star Project (EU DG XIII), “Enterprise Management”, distributed by Paul Cooper on the Manchester CORBAmed meeting, May 1998.
[Stephanidis97a] C. Stephanidis, “User Interfaces for All: Developing Interfaces for Diverse User Groups”, in A. Jameson, C. Paris, C. Tasso (Eds.), “User Modeling: Proceedings of the Sixth International Conference, UM97”, Vienna, New York, Springer Wien New York, a CISM, 1997.
[Stephanidis97b] C. Stephanidis, D. Akoumianakis, “Preference-Based Human Factors Knowledge Repository for Designing User Interfaces”, International Journal of Human-Computer Interaction, Vol. 9, No. 3, pp. 283-318, 1998.
[Sycara96] K. Sycara and D. Zeng. “Coordination of Multiple Intelligent Software Agents.” Int. J. of Cooperative Information Systems, vol 5, no. 2/3, pages 181-211, 1996.
[Synapses97a] W. Grimson and D. Berry. "Synapse Federated Healthcare Record Server: Software Requirements Specification of the Federated Healthcare Record Server", HC 1046, Synapses Deliverable User 1.1.1 (Part B), Dublin Institute of Technology, 1997.
[Synapses97b] D. Kalpa "Synapse Federated Healthcare Record Server: Synapses Object Model and Object Dictionary" HC 1046, Synapses Deliverable User 1.3.2, University of London, April 97.
[TelemedProject95] Telemed Project, Los Alamos National Laboratory, 1995 (http://www.acl.lanl.gov/TeleMed).
[Teng95] J. T. C. Teng and W. J. Keffinger, “Business Process Redesign and Information Architecture: Exploring the Relationships”, Data Base, Vol. 26, No. 1, pp. 30-42, February 1995.
[Thomas96] C. Thomas, N. Bevan, “Usability Context Analysis: A Practical Guide Version 4.02”, Crown Copyright 1996 (US@hci.npl.co.uk).
[Tonnesen96] A. S. Tonnesen, “Problem Oriented Encounter (Progress) notes”, University of Texas – Houston Health Science Center, 1996 (http://oac3.hsc.uth.tmc.edu/~atonnese/eprprogn.html).
[Tsiknakis96] M. Tsiknakis, D. G. Katehakis, S. Orphanoudakis, “Intelligent Image Management in a Distributed PACS and Telemedicine Environment”, IEEE Communications Magazine, Vol. 34, No. 7, pp. 36-45, July 1996 (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/ieee96/ieee96.html).
[Tsiknakis97] M. Tsiknakis, C. E. Chronaki, S. Kapidakis, C. Nikolaou, and S. C. Orphanoudakis, "An Integrated Architecture for the Provision of Health Telematic Services based on Digital Library Technologies", International Journal on Digital Libraries, Special Issue on "Digital Libraries in Medicine", vol. 1(3), 257-277, 1997. (http://www.ics.forth.gr/ICS/acti/cmi_hta/publications/dglib97/dglib97.html).
[XIWT94] Cross Industry Working Team. “An Architectural Framework for the National Information Infrastructure.” White paper, September 1994. (http://www.xiwt.org/).
[Yeong95] W. Yeong, T. Howes, and S. Kille. “RFC 1777: Lightweight Directory Access Protocol”, March 1995. (http://ds.internic.net/rfc/rfc1777.txt)