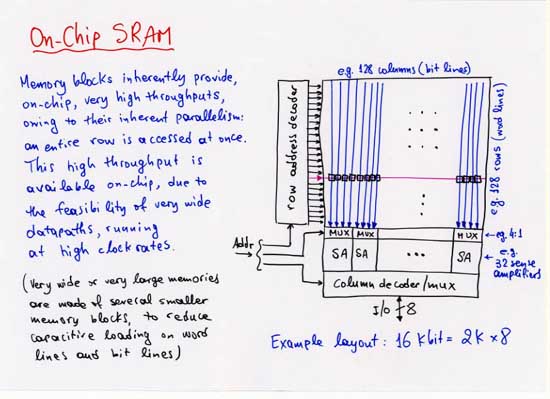
The plots, below, show examples of cost (area, power) and performance (cycle time) for on-chip static RAM blocks, as functions of capacity, number of ports, and port width. These examples are inspired by and representative of various real 0.35-micron CMOS technologies of about 1998, but are not the same with any one such technology.
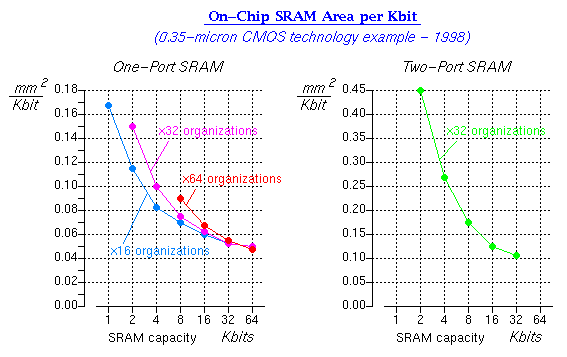
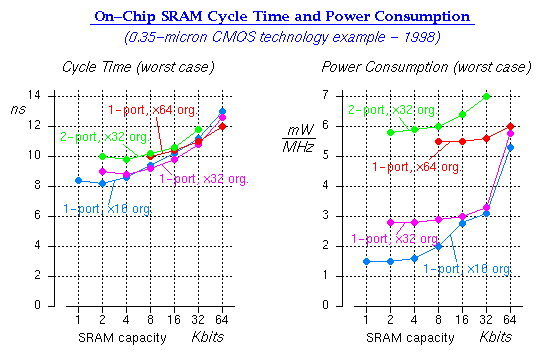
![]()
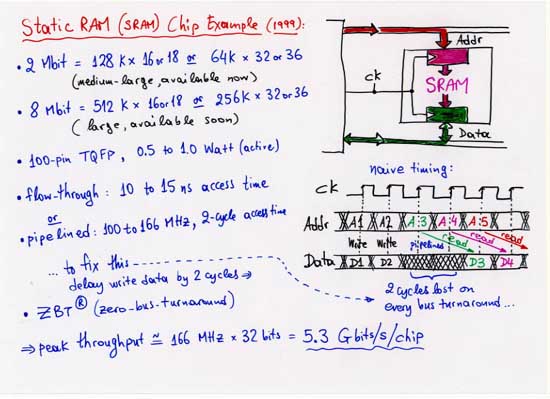
Example:
Micron's
8 Mbit, pipelined, "zero-bus-turnaround (ZBT)" SRAM.

![]()
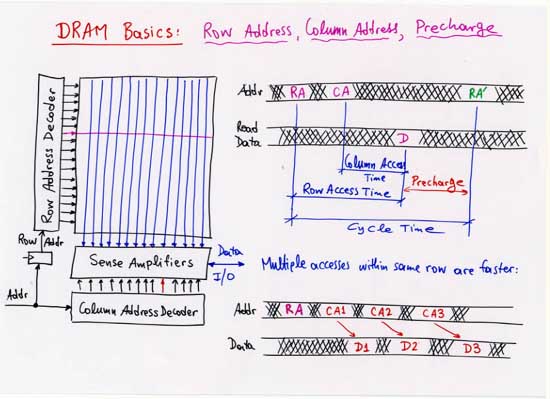
Example:
Micron's
256 Mbit SDRAM's.

![]()
For more information on
Rambus,
you can start with the
Technology Overview (PDF) document
from the
Development Support - Getting Started section.
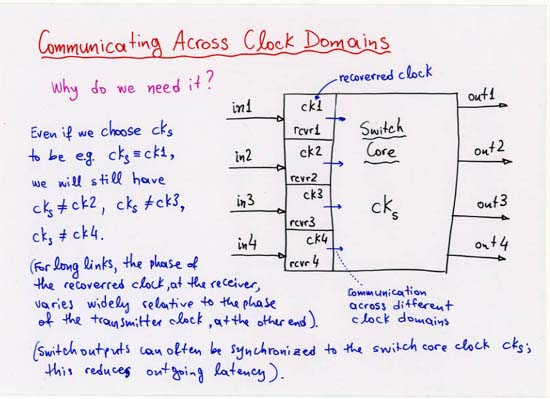
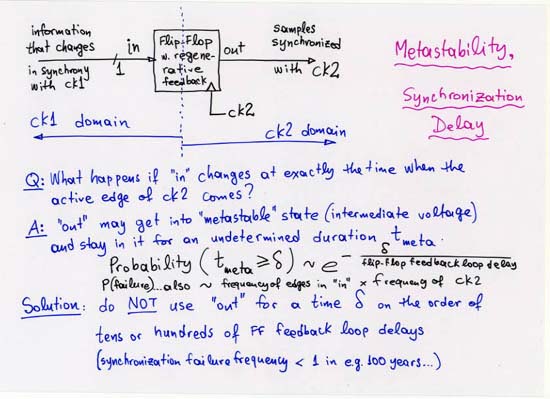
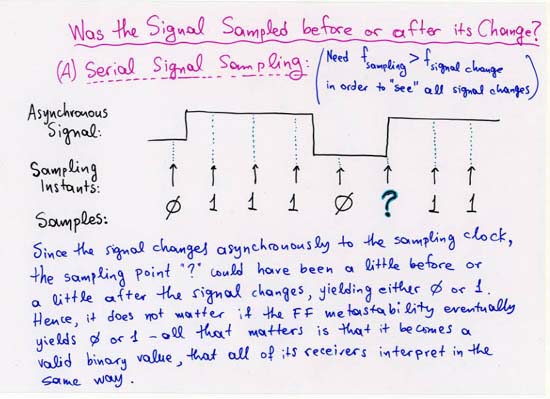
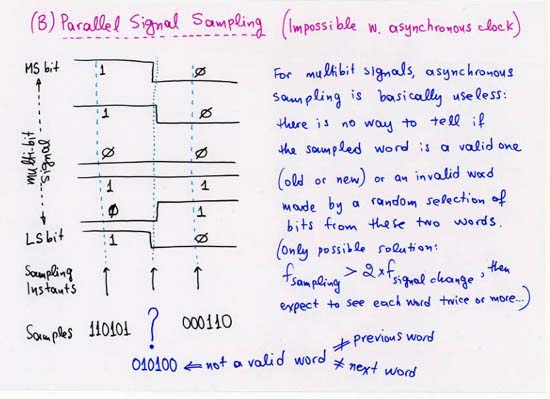
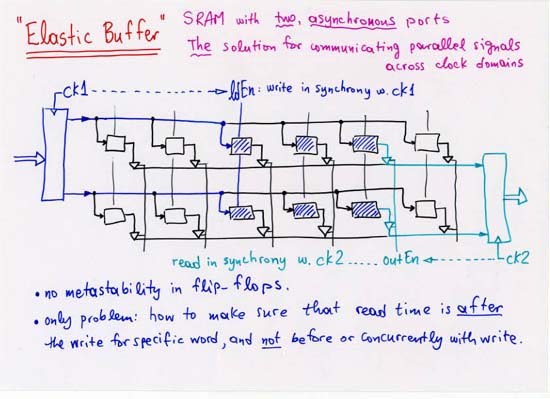
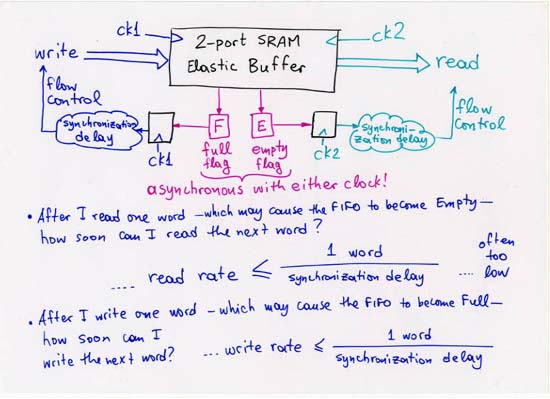

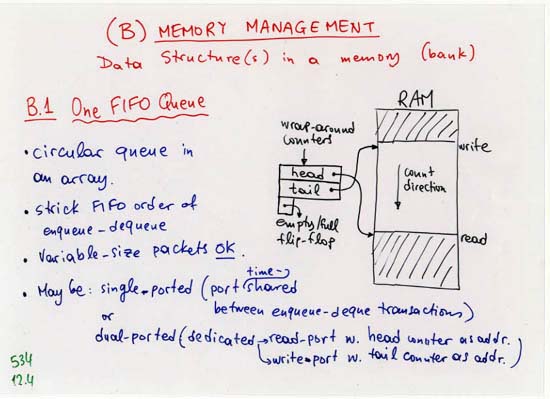
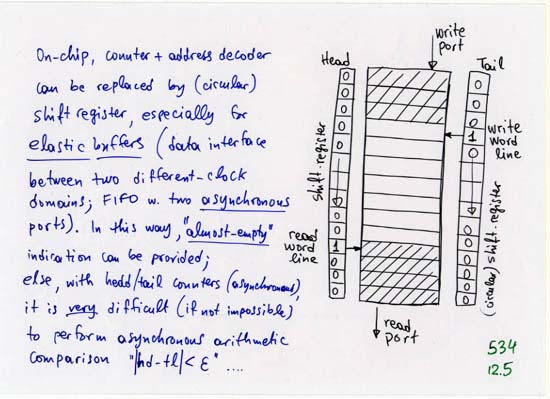
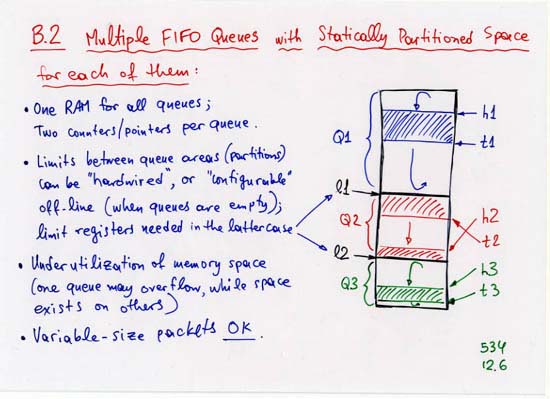
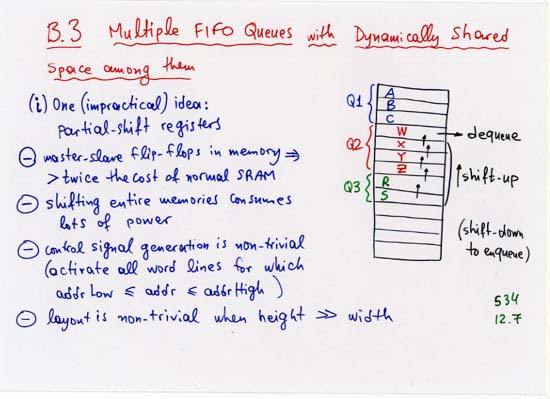
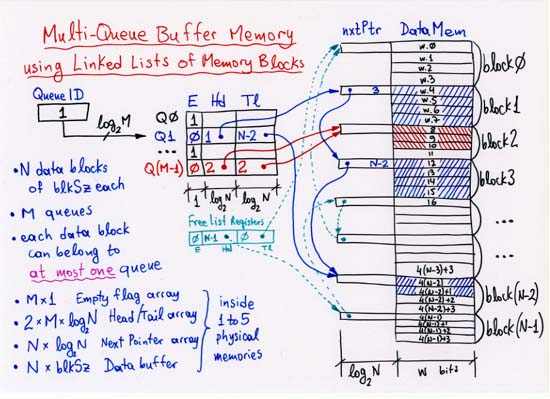
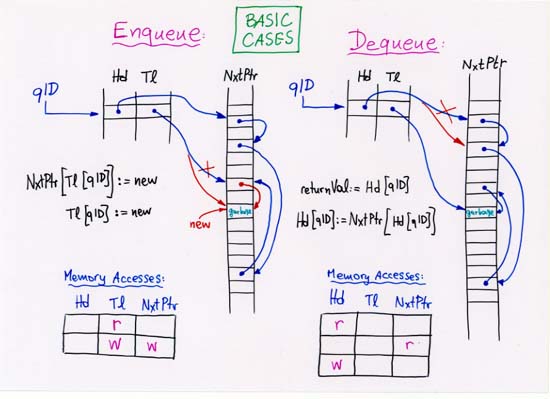
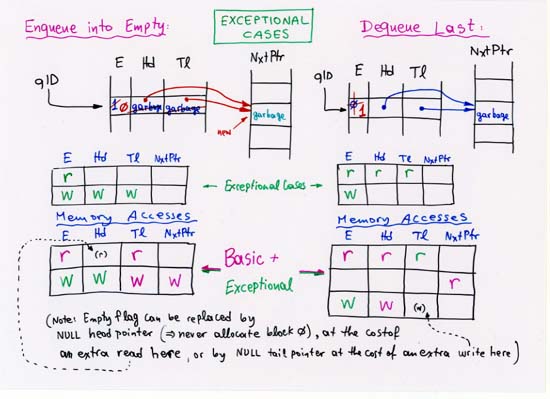

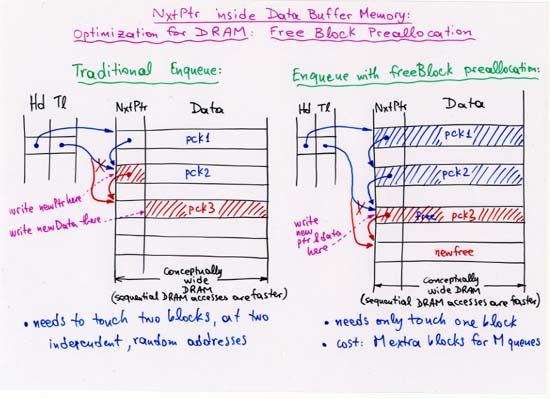
CORRECTION: line 4 (separate, off-chip Head, Tail, NxtPtr memories):
enqueue latency is 3 --not 2.
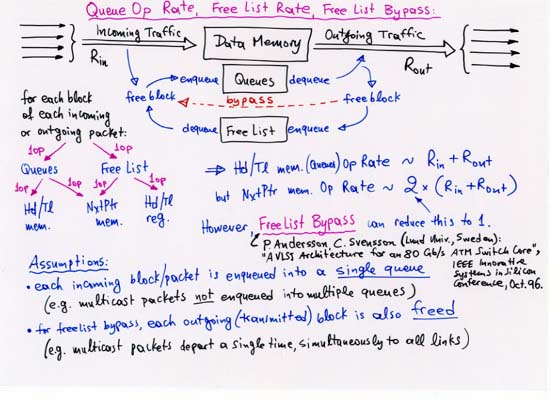
NOTE (b): to achieve peak throughput,
by overlapping successive queue operations,
the latency of individual operations will often have to be increased.