




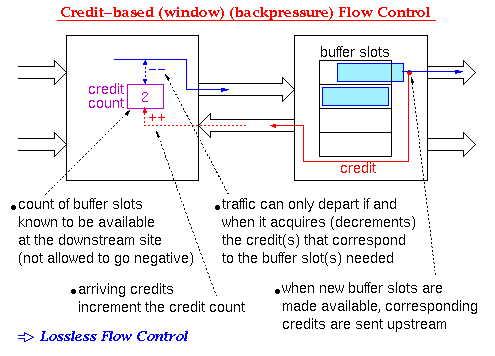
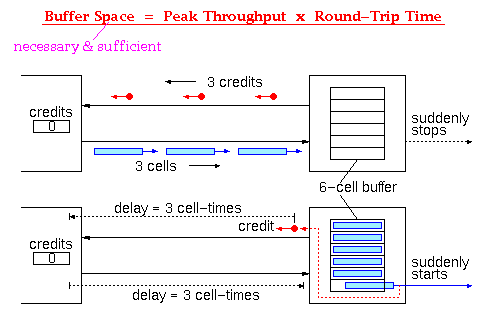
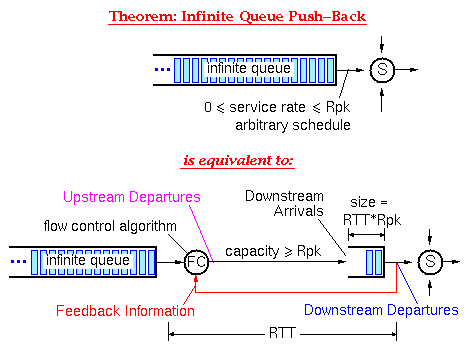
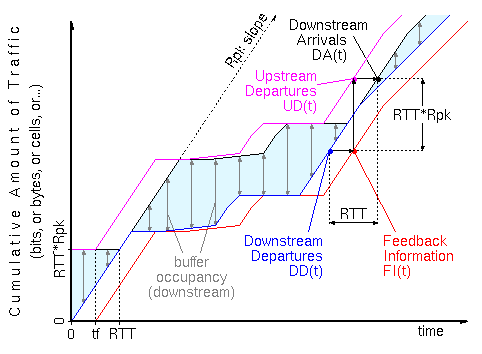






Static Allocation of Windows to Connections:
The simplest organization
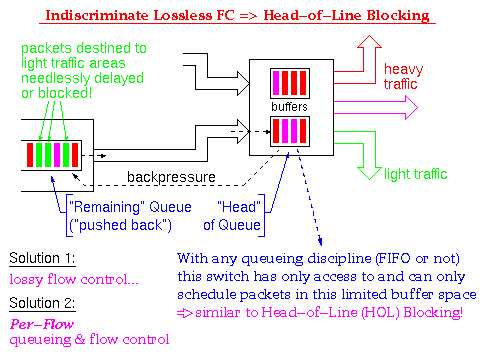
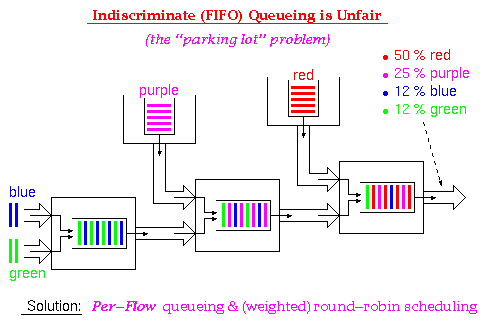
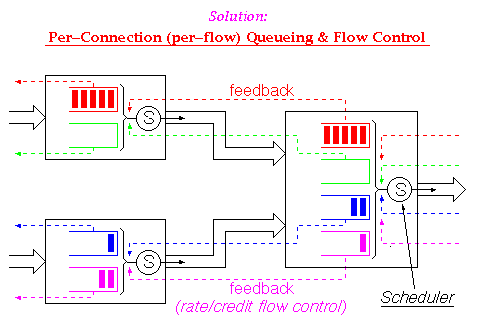
for lossless flow control without HOL blocking,
--i.e. per-connection queueing and per-connection (credit) FC--
is to statically dedicate one window's worth of buffer space
to each and every connection that passes through the switch.
Given the above figures,
this is economically viable
if the number of connections is relatively restricted
(e.g. up to a few thousand),
or if the ratio of peak to average throughput per connection
does not exceed a few thousand.
The numbers go as follows in this latter case:
call PAR this peak-to-average ratio,
and assume for simplicity
that it is the same for all connections on the given link
(i.e. consider the largest of these ratios, among all connections).
Then,
the window size for connection VCi is:
RTT * peakThroughput(VCi) = RTT * PAR * avgThroughput(VCi).
The sum of the average throughput
of all connections passing through a given link
cannot exceed the throughput of the link.
Hence, the total size of all of the above windows,
for all connections VCi,
is no greater than RTT * PAR * throughput(Link) = PAR * windowL,
in the above terminology.
If PAR is no more than a few thousand,
this scheme is economically viable
according to the figures presented above.
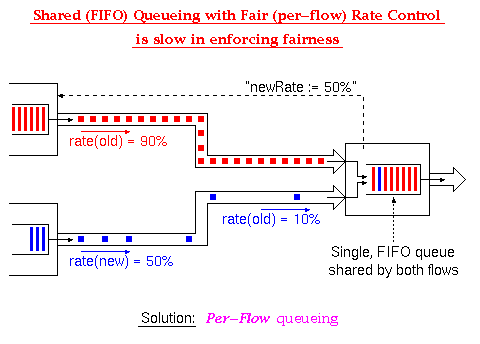
Dynamically Sharing the Buffer Space among the Connections:
Even though the static allocation scheme above
is economically viable in many or most practical situations,
it is usually possible to achieve comparably good performance
using even less memory space for buffering.
This is achieved by dynamically sharing the available buffer space
among all active connections,
according to various management algorithms.
All such algorithms restrict each connection VCi
to never use more than windowSize(VCi) = RTT * peakThroughput(VCi)
space in the shared buffer.
However, given that not all windows of all connections
can fit in the available buffer space at the same time,
the management algorithms place additional restrictions
on the use of buffer space when the total buffer starts filling up.
Two such management algorithms that have appeared in the literature are:
[OzSV95] C. Ozveren, R. Simcoe, G. Varghese: ``Reliable and Efficient Hop-by-Hop Flow Control'', IEEE Journal on Sel. Areas in Communications, vol. 13, no. 4, May 1995, pp. 642-650.
[KuBC94] H.T. Kung, T. Blackwell, A. Chapman: ``Credit-Based Flow Control for ATM Networks: Credit Update Protocol, Adaptive Credit Allocation, and Statistical Multiplexing'', Proceedings of the ACM SIGCOMM '94 Conference, London, UK, 31 Aug. - 2 Sep. 1994, ACM Comp. Comm. Review, vol. 24, no. 4, pp. 101-114.
The [OzSV95] is the simpler of the two proposals; it calls for two window sizes for each connection, one equal to the full RTT * peakThroughput(VCi) which is applied when the total buffer is relatively empty, and another, reduced window size that is applied when the buffer starts filling up.
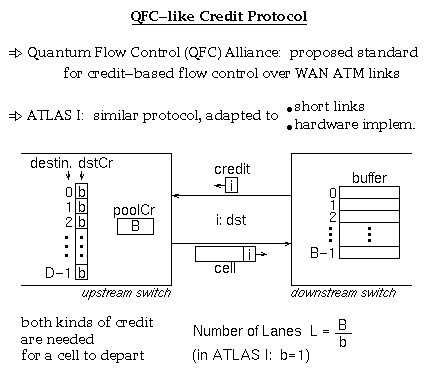
Subsequent to the above two studies, an alliance of some 20 commercial companies was formed, who developed and published a specification for a credit-based flow control protocol on a per-connection basis, with dynamically shared buffer space. This is known as the QFC ("Quantum Flow Control") protocol. A number of companies in the QFC alliance have incorporated the QFC protocol in products of theirs. Standardization work for this protocol is under way, through the ITU-T; within the ITU-T, this protocol is known as "Controlled Dynamic Transfer" (CDT). The QFC protocol and various documentation related to it can be found at the following web site:
[QFC95] Quantum Flow Control Alliance: ``Quantum Flow Control: A cell-relay protocol supporting an Available Bit Rate Service'', version 2.0, July 1995; http://www.qfc.org
The QFC protocol is even simpler than the [OzSV95] proposal: it specifies a window per connection, whose size stays fixed independent of the overall buffer occupancy. In addition to the per-connection windows, QFC, like [OzSV95], uses a ``global window'' per link to make sure that the overall buffer does not overflow. In order for a cell to depart, it must acquire both a credit for its own connection's window, and a credit for the overall global window. Normally, the global window is smaller than the sum of the windows of all connections that traverse the link.
[Copyright Notice: The rest of this section is presented by borrowing material from the ASICCOM/ATLAS project of ICS-FORTH; this material is owned (copyright'ed) by ICS-FORTH, and is presented here with the permission of ICS-FORTH].
ATLAS I is a 10 Gb/s single-chip ATM switch that supports credit-based flow control (multilane backpressure).
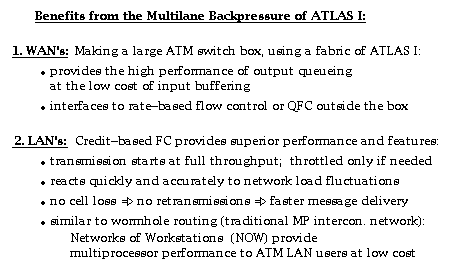
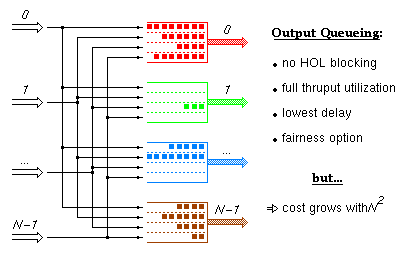
Output queueing is the ideal switch architecture from the point of view of performance, but it becomes impractical for large valency switches because its cost grows with the square of the number of links. Below we will see how ATLAS I based switching fabrics with internal backpressure emulate this architecture so as to provide comparatively high performance at a significantly lower cost. In this and the next two trancparencies, the color of a cell indicates the output port of the fabric that this cell is destined to (in the ATLAS I based fabric, this will identify the flow group that the cell belongs to).
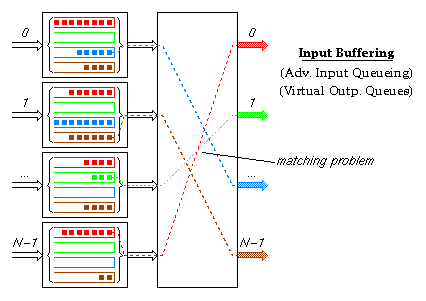
Input buffering (otherwise called advanced input queueing, or virtual output queues at the inputs) is one method by which designers have tried to provide high switch performance at reasonable cost. It avoids the head-of-line blocking problem of FIFO input queueing by providing multiple logical queues (one per output) in each input buffer. The switch part of this architecture must solve a matching problem during each cell time: for each input buffer, choose one of the cell colors present in it, so that no two input buffers have the same color chosen, and so that the number of colors chosen is maximized (or other performance criteria, e.g. fairness). For large valency switches, this matching problem is extremely hard to solve quickly and with good performance. Bellow we will see how ATLAS I based switching fabrics with internal backpressure emulate the solution of this matching problem in a progressive and distributed manner.
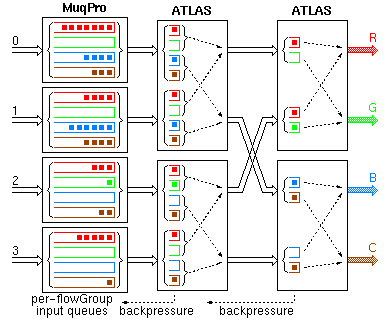
The effect of the ATLAS backpressure is to push most of the output queue cells back near the input ports. The head cells of the output queues, however, are still close to their respective output ports. The fabric operates like an input-buffered switch where the ATLAS chips implement the arbitration and scheduling function in a distributed, pipelined fashion. In every link, all connections going to a given output port of the fabric form one flow group (colors correspond to flow groups). Each MuqPro maintains separate logical queues for each flow group. For simplicity, this transparency only shows a 4x4 fabric made of 2x2 switch elements --this architecture, however, scales perfectly well to very large switching fabrics. In this switching fabric, the only external memories are those attached to the MuqPro's, whose cost is the same as in input buffering. In order for the cost to be kept at that low level, the building blocks of the switching fabric (i.e. ATLAS) must not use off-chip buffer memory. Since buffer memory in the switching elements has to be restricted to what fits on a single chip, backpressure is the method to keep this small memory from overflowing all the time. Performance-wise, this switching fabric offers properties comparable to those of output queueing. Saturation throughput is close to 1.0 even with few lanes (see below). No cell loss occurs in the fabric --cells are only dropped when the (large) MuqPro queues fill-up. Traffic to lightly loaded destination ports (e.g. G) is isolated from hot-spot outputs (e.g. R) as verified by simulation (see below).
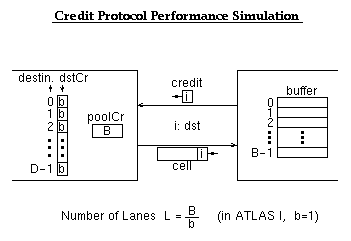
We simulated Banyan networks like the ATLAS-MuqPro backpressured fabric above. Flow groups corresponded to destinations. The switch elements simulated were implementing a credit flow control protocol that is a generalization of the ATLAS I protocol: the flowGroup (destination) credits were initialized to any number --not just 1, as in ATLAS I.
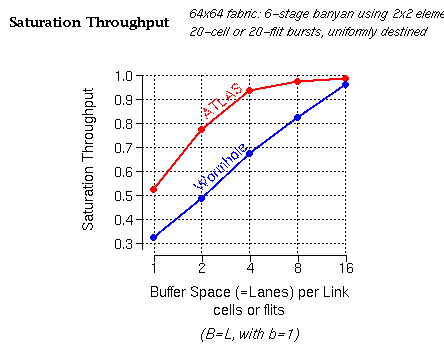
We see that a modest buffer space --around 8 to 16 cells per incoming link (for the low priority class)-- suffices for the outgoing links to reach full utilization (presumably, by low priority traffic, which fills in whatever capacity remains unused by higher priority traffic). The ATLAS protocol (red line) performs better than the traditional multilane wormhole protocol for the reasons outlined below.
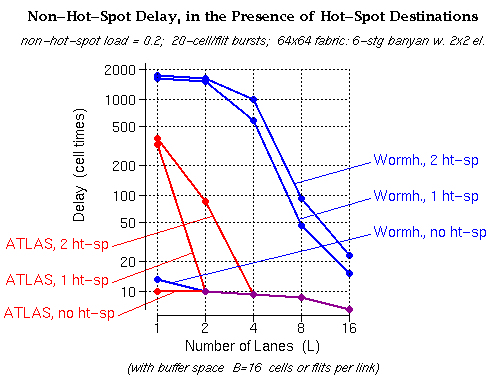
With the ATLAS protocol, when the number of lanes is larger than the number of hot-spot output ports of the fabric (1 or 2 ports --upper two red curves), the delay to the non-hot-spot outputs remains unaffected by the presence of hot-spots (it is the same as when there are no hot-spot outputs --bottom red curve). This is precisely the ideal desired behavior for hot-spot tolerance.
