| CS-534: Packet Switch Architecture
Spring 2003 |
Department of Computer Science © University of Crete, Greece |
Exercise Set 5:
Segmented Packets in Linked-List Multi-Queue Memories
Normally assigned: Wed. of week 5 -- Normally due: Wed. of week 6
This year assigned: Mon. 24 Mar. 2003 (wk 6) -- due: Mon. 31 Mar. 2003 (wk 7)
5.1 Segment Size Selection
--- Optional-Answer Exercise: ---You have to read carefully this exercise, understand it, and think about it for at least 40 minutes. However, you are allowed not to answer it, especially if it looks like answering it will take you much more than the above time.
This exercise is a continuation and generalization of exercise 4.2. In this exercise you have to deduce a mathematical formulation for the smallest possible segment size that will not increase the segment access rate beyond the value imposed by minimum packet size. Let us first define the necessary terminology and link technology parameters:
- rl: gross line rate. This is the link bit rate including overhead. For example, for gigabit ethernet, this is 1.25 Gbits/s, given the 8B/10B encoding on the line (see exercise 1.4).
- rnet: net line rate. This is the net (useful) bit rate, excluding the (proportional) overhead of line encoding (the "proportional" overhead is the overhead whose size increases in proportion to the packet size). For example, for gigabit ethernet, rnet is 1.0 Gbits/s. For ATM over SONET, rnet = (87/90) x rl (see exercise 1.3) (this is assuming that all 53 bytes of each ATM cell are stored in memory).
- smin: minimum packet size. This is the size of the smallest packet as stored in memory; For example, for IP, this is taken to be 40 bytes.
- spd_min: minimum padded packet size. For ethernet, packets that are smaller than spd_min are first padded to spd_min and then transmitted on the line; packets equal to or larger than spd_min are not paddded. The padding is not written to memory. As we discussed in exercise 4.2, spd_min is 46 bytes in gigabit ethernet.
- sovrh: size of the fixed per-packet overhead. This is the fixed-size overhead that is added to each packet when transmitted on the line; its size does not grow in proportion to the packet size, as is the case for the rl-rnet overhead. This overhead is not written to memory. In the case of gigabit ethernet, this is 38 bytes (12-byte interframe gap, plus 8-byte preamble, plus 14-byte ethernet header, plus 4-byte ethernet CRC).
- sp: packet size, for an arbitrary packet. On the line, this is always spd_min or greater; in memory, this is always smin or greater.
- tl(sp): time on the line of a packet of size sp (the time it takes to transmit or receive this packet on the line, measured from a "starting point" of this packet to the same starting point of the next packet, when packets appear back-to-back on the line). For packets of size up to spd_min, this is: tl(sp) = (spd_min + sovrh) / rnet; for larger packets, the packet line time is: tl(sp) = (sp + sovrh) / rnet.
- sseg: the segment size of the buffer memory; each packet is written to memory after being segmented into an integer number of segments of this size. This segment size is the design parameter that we want to determine.
- nseg(sp): the number of segments into which a packet of size sp is segmented. This is the ceiling of sp/sseg (the smallest integer not below this ratio) (sp here is the size of the packet as written in memory, hence it can be as small as smin).
- tseg(sp): time available for each segment access in the buffer memory, when the packet size is sp. This is: tseg(sp) = tl(sp) / nseg(sp).
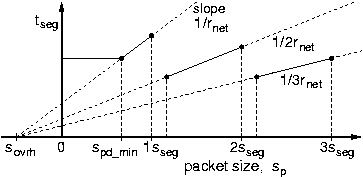 We want to find the smallest segment size sseg
that will maximize the worst-case available segment time
tseg(sp)
for all packet sizes sp.
Start by plotting the available segment time, tseg,
as a function of packet size, sp,
for a given, fixed segment size, sseg,
as in the figure on the right.
Observe the properties of the plot:
which (discrete) values of packet size
are the "most critical" ones?
Clearly, this smallest segment size
must be at least as large as spd_min,
because all packets of size spd_min or less take
(spd_min + sovrh) / rnet
line time;
if the segment size were less than spd_min,
some packets (e.g. packets of size spd_min)
would require a segment time less than this line time
(i.e. a sub-multiple of this minimum packet line time).
Hence,
the worst-case segment time cannot be higher than:
(spd_min + sovrh) / rnet.
Your task is to find the smallest segment size sseg
for which the available segment time
never falls below the above value,
for all packet sizes sp > spd_min.
Given the above "most critical" discrete values of packet size,
conversely, which (discrete) values of segment size sseg
are the "most critical" ones?
Give some kind of a mathematical formulation
or an algorithm for determining the segment size sought.
Finally,
apply your solution to the cases of
(a)
IP-over-SONET, as it was (ill- ?) defined in exercise
4.2(c-d);
(b)
Gigabit Ethernet, as in exercise
4.2(e-f).
We want to find the smallest segment size sseg
that will maximize the worst-case available segment time
tseg(sp)
for all packet sizes sp.
Start by plotting the available segment time, tseg,
as a function of packet size, sp,
for a given, fixed segment size, sseg,
as in the figure on the right.
Observe the properties of the plot:
which (discrete) values of packet size
are the "most critical" ones?
Clearly, this smallest segment size
must be at least as large as spd_min,
because all packets of size spd_min or less take
(spd_min + sovrh) / rnet
line time;
if the segment size were less than spd_min,
some packets (e.g. packets of size spd_min)
would require a segment time less than this line time
(i.e. a sub-multiple of this minimum packet line time).
Hence,
the worst-case segment time cannot be higher than:
(spd_min + sovrh) / rnet.
Your task is to find the smallest segment size sseg
for which the available segment time
never falls below the above value,
for all packet sizes sp > spd_min.
Given the above "most critical" discrete values of packet size,
conversely, which (discrete) values of segment size sseg
are the "most critical" ones?
Give some kind of a mathematical formulation
or an algorithm for determining the segment size sought.
Finally,
apply your solution to the cases of
(a)
IP-over-SONET, as it was (ill- ?) defined in exercise
4.2(c-d);
(b)
Gigabit Ethernet, as in exercise
4.2(e-f).
5.2 Queue Operation Latency and Throughput
In section 3.4.2, 4th transparency, we saw a table of enqueue and dequeue latencies and throughput, for various degrees of memory access parallelism, i.e. different numbers of separate memory blocks, on-chip or off-chip. This table assumed fall-through off-chip SRAM, and that an off-chip dependent access (address of second access = read data of first access) can occur, at the earliest, two cycles after the access it depends on.Assume now that the off-chip SRAM chip(s) are synchronous (pipelined), QDR or ZBT SRAM's, like the ones seen in class (section 3.2). In that case, dependent off-chip accesses can occur, at the earliest, three cycles after one another: if address A1 is valid on the address bus on clock edge number 1, read data D(A1) will be valid on the data bus on clock edge number 3; assuming that the controller chip is fast enough, it can then drive these data D(A1) back on the address bus during the immediately succeding clock cycle --the clock cycle between edges 3 and 4-- so that, after the drive delay, they are valid and stable on clock edge number 4.
Under this new assumption, recalculate all the latency values for the enqueue and dequeue operation in most of the system configurations shown on that 4th transparency, as described below. To be precise, use the following definition of latency: the latency of an operation is the time, in clock cycles, between initiations of two successive similar operations, assuming that no operation overlap occurs, i.e. assuming that the first memory access for the second operation occurs after the last memory access for the first operation.
For each operation (enqueue or dequeue) and for each of the system configurations below, show the schedule of memory access, i.e. which memory(ies) are accessed in each clock cycle, at which address. For the QDR/ZBT off-chip SRAM's, the cycle during which you show the access corresponds to the cycle during which the controller chip drives the address on the address bus; this address is valid on the address bus on the clock edge that terminates this clock cycle. If you do not have the time to derive this schedule of memory access for all of the system configurations shown on that 4th transparency, do it at least for the following configurations: (i) all of Head, Tail, and NxtPtr in a single, 1-port, off-chip memory; (ii) like case (i), but with the Empty flags in an on-chip memory; (iii) Empty, Head, and Tail in 1-port, on-chip memories, and NxtPtr in 1-port, off-chip memory.
5.3 Multiple-Packets-per-Block Queue Organization
When variable-size packets are kept in a buffer memory, in multiple queues of packets using linked lists of memory blocks (segments) as in section 3.4, the memory block (segment) size is chosen, usually, on the same order or slightly larger than the minimum packet size, and each new packet is stored beginning with a fresh block --i.e. no block contains data from two different packets. The last block of each packet will often be partially filled, even if it is not the last block on its queue.In this exercise, you will study an alternative scheme: the packets that belong to a same queue are stored contiguously after one another, starting in the next byte of the same memory block after the last byte of their previous packet, whenever that previous packet finishes before the end of a block. Thus, the memory block size may be relatively large, because the only unused space is at the beginning of the first block of each queue and at the end of the last block of each queue --not at the end of the last block of each packet as in the other scheme. (If the number of queues is very large, on the same order as the number of packets in the buffer memory, then this scheme makes little sense).
Assume that no special marker or pointer is needed to indicate the end of each packet (and hence the beginning of the next packet), because each packet includes enough information to indicate its precise length (e.g. a length field, or a special end-of-packet pattern inside its data). This is important, given that the number of packet boundaries inside a single memory block may be potentially large, hence keeping end-of-packet markers or pointers in the queue data structures would be akward. Thus, the only management data needed per memory block is a pointer to the next block on its queue. The head and tail pointers of each queue, on the other hand, need to be full pointers into the buffer memory, pointing to a specific byte position inside a specific block --not merely pointers to (the beginning of) a block.
Analyze the time cost of this scheme: is it better, worse, or similar to the cost of the "usual" scheme? By "time cost" we mean the number of management operations and memory accesses needed when enqueueing an incoming packet into a queue or when dequeueing a departing packet from a queue. Include the free list operations in your analysis. Analyze especially the worst case, and try to analyze the average case too.
| Up to the Home Page of CS-534
|
© copyright
University of Crete, Greece. Last updated: 24 Mar. 2003, by M. Katevenis. |