Brief description
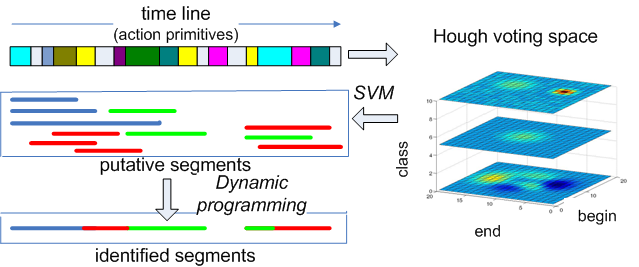
In this work, we provide a discriminative framework for online simultaneous segmentation and classification of visual actions, which deals effectively with unknown sequences that may interrupt the known sequential patterns. To this end we employ Hough transform to vote in a 3D space for the begin point, the end point and the label of the segmented part of the input stream. An SVM is used to model each class and to suggest putative labeled segments on the timeline. To identify the most plausible segments among the putative ones we apply a dynamic programming algorithm, which maximises an objective function for label assignment in linear time. The performance of our method is evaluated on synthetic as well as on real data (Weizmann and Berkeley multimodal human action database). The proposed approach is of comparable accuracy to the state of the art for online stream segmentation and classification and performs considerably better in the presence of previously unseen actions..
The outline of the method
Sample results
A video with action recognition experiments.
Contributors
- Dimitrios Kosmopoulos, Konstantinos Papoutsakis, Antonis Argyros.
- This work was partially supported by the EU-FP7 integrated project HOBBIT and ACANTO.
Relevant publications
- D. Kosmopoulos, K. Papoutsakis and A.A. Argyros, "A framework for online segmentation and classification of modeled actions performed in the context of unmodeled ones", IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) (to appear), IEEE, July 2016.
- D. Kosmopoulos, K. Papoutsakis and A.A. Argyros, "Online segmentation and classification of modeled actions performed in the context of unmodeled ones", In British Machine Vision Conference (BMVC 2014), BMVA, Nottingham, UK, September 2014.
The electronic versions of the above publications can be downloaded from my publications page.