Postgraduate scholar - Research assistant
Computational Vision & Robotics Laboratory,
Institute of Computer Science, FORTH

I am a Ph.D student at the Computer Science Department of University of Crete in Heraklion, Greece and a postgraduate scholar at the Computational Vision & Robotics Lab (CVRL) at the Institute of Computer Science of FORTH, where I closely work with my supervisor Prof. Antonis A. Argyros. My research interests are computer vision, machine learning and robotics, especially topics related to human motion analysis, action understanding, human-robot interaction and vision for robots.
For details please see my publications page or my Google scholar profile.
Computational Vision & Robotics Laboratory,
Institute of Computer Science, FORTH
Computational Vision & Robotics Laboratory,
Institute of Computer Science, FORTH
Computational Vision & Robotics Laboratory,
Institute of Computer Science, FORTH
Ph.D. candidate in Computer Science
Computer Science Department, University of Crete, Greece
Master of Science in Computer Science
Computer Science Department, University of Crete, Greece
Diploma in Computer Engineering & Informatics
School of Engineering, University of Partas, Greece

My work during the Ph.D studies is summarized as "Computational methods for understanding activities of human and their interaction with objects in videos", under the supervision of Professor Antonis Argyros. My research interests are in the field of computer vision, machine learning and human-robot interaction. My strong motivation for research on these prominent scientific areas and problems stems from the fact that we, as humans, have a remarkable ability to perceive rapidly the appearance, structure, motion and interactions of humans and objects and we can analyze the ongoing activities or predict intentions by combining perceptual and contextual information together common-sense reasoning. Developing technical systems with similar capabilities is a really fascinating goal.
The applicability of computer vision and machine learning methods on action recognition is often limited by the availability of labeled data in videos or the large amount of video data and the laborious training procedures required to learn a limited number (tens) of human action categories. My main focus during my doctoral studies has been to devise novel solutions for understanding human actions and the interactions of humans with objects in videos. Towards achieving this goal, I have worked on both aspects of supervised methodologies for action detection & recognition in untrimmed video sequences and on unsupervised methodologies for the discovery of common activities in pairs of untrimmed video sequences without any prior knowledge on the number, labels or models of the actions.
I have contributed in the following EU-funded projects during my work at the Computational Vision & Robotics Lab of ICS, FORTH-Hellas under the supervision of Prof. Antonis Argyros:
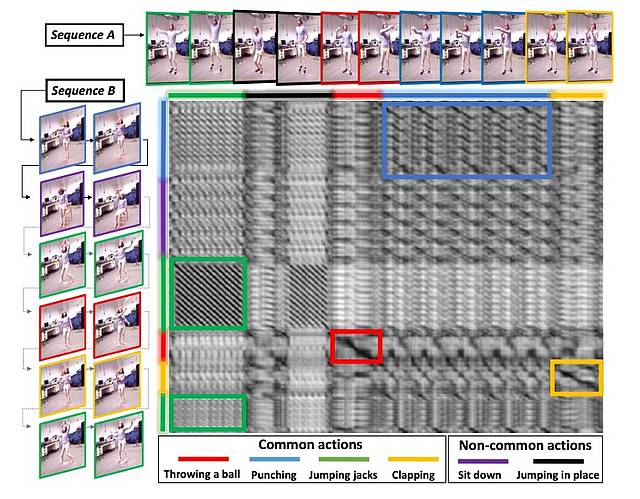
We propose a totally unsupervised solution to this problem. No a-priori model of the actions is assumed to be available. The number of common sub-sequences may be unknown. The sub-sequences can be located anywhere in the original sequences, may differ in duration and the corresponding actions may be performed by a different person, in different style The unsupervised discovery of common patterns in images and videos is considered an important and unsolved problem in computer vision. We are interested in the temporal aspect of the problem and focus on action sequences (sequences of 3D motion capture data or video data) that contain multiple common actions
We treat this type of temporal action co-segmentation as a stochastic optimization problem that is solved by employing Particle Swarm Optimization (PSO). The objective function that is minimized by PSO capitalizes on Dynamic Time Warping (DTW) to compare two action sub-sequences.
The electronic versions of the above publications can be downloaded from the publications page.
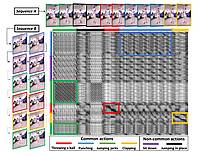
In this work, we provide a discriminative framework for online simultaneous segmentation and classification of visual actions, which deals effectively with unknown sequences that may interrupt the known sequential patterns. To this end we employ Hough transform to vote in a 3D space for the begin point, the end point and the label of the segmented part of the input stream. An SVM is used to model each class and to suggest putative labeled segments on the timeline. To identify the most plausible segments among the putative ones we apply a dynamic programming algorithm, which maximises an objective function for label assignment in linear time. The performance of our method is evaluated on synthetic as well as on real data (Weizmann and Berkeley multimodal human action database). The proposed approach is of comparable accuracy to the state of the art for online stream segmentation and classification and performs considerably better in the presence of previously unseen actions.
D. Kosmopoulos, K. Papoutsakis and A.A. Argyros, "A framework for online segmentation and classification
of modeled actions performed in the context of unmodeled ones", IEEE Transactions on Circuits
and Systems for Video Technology (TCSVT), IEEE, July 2016.
BibTex
D. Kosmopoulos, K. Papoutsakis and A.A. Argyros, "Online segmentation and classification of modeled
actions performed in the context of unmodeled ones", In British Machine Vision Conference
(BMVC 2014), BMVA, Nottingham, UK, September 2014.
PDF
BibTex
More details and the electronic versions of the above publications can be downloaded from the publications page.
The electronic versions of the above publications can be downloaded from the publications page.
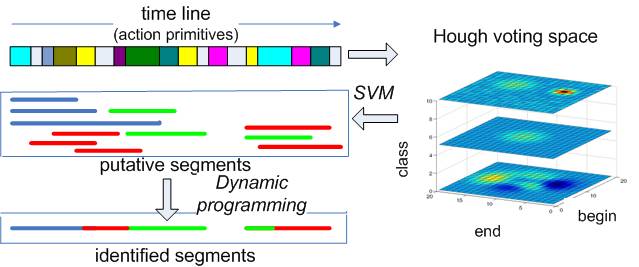
We propose a new approach for vision-based gesture recognition to support robust and efficient human robot interaction towards developing socially assistive robots. The considered gestural vocabulary consists of five, user specified hand gestures that convey messages of fundamental importance in the context of human-robot dialogue. Despite their small number, the recognition of these gestures exhibits considerable challenges. Aiming at natural, easy-to-memorize means of interaction, users have identified gestures consisting of both static and dynamic hand configurations that involve different scales of observation (from arms to fingers) and exhibit intrinsic ambiguities. Moreover, the gestures need to be recognized regardless of the multifaceted variability of the human subjects performing them. Recognition needs to be performed online, in continuous video streams containing other irrelevant/unmodeled motions. All the above need to be achieved by analyzing information acquired by a possibly moving RGBD camera, in cluttered environments with considerable light variations. We present a gesture recognition method that addresses the above challenges, as well as promising experimental results obtained from relevant user trials.

Illustration of the supported gestures. The correspondence between gestures and physical actions of hands/arms are as follows: (a) “Yes": A thumb up hand posture. (b) “No": A sideways waiving hand with extended index finger. (c) “Reward": A circular motion of an open palm at a plane parallel to the image plane. (d) “Stop/cancel": A two-handed push forward gesture. (e) “Help": two arms in a cross configuration.

Illustration of intermediate results for hand detection. (a) Input RGB frame. (b) Input depth frame It. (c) The binary mask Mt where far-away structures have been suppressed and depth discontinuities of It appear as background pixels. Skeleton points St are shown superimposed (red pixels). (d) A forest of minimum spanning trees is computed based on (c), identifying initial hand hypotheses. Circles represent the palm centers. (e) Checking hypotheses against a simple hand model facilitates the detection of the actual hands, filtering out wrong hypotheses. (f) Another example showing the detection results (wrist, palm, fingers) in a scene with two hands.
D.Michel, K. Papoutsakis, A.A. Argyros, “Gesture recognition for the perceptual support of assistive robots”,
International Symposium on Visual Computing (ISVC 2014), Las Vegas, Nevada, USA, Dec. 8-10, 2014.
BibTex
D. Michel, K. Papoutsakis and A.A. Argyros, "Gesture Recognition Apparatuses, Methods and Systems for Human-Machine Interaction",
United States Patent No 20160078289, Filed: 16 September, 2015, Published: 17 March, 2016.
BibTex
PDF
The electronic versions of the above publications can be downloaded from the publications page.

In the context of "Hobbit-The mutual care robot" we have researched several approaches towards developing visual competencies for socially assistive robots within the framework of the HOBBIT project. We show how we integrated several vision modules using a layered architectural scheme. Our goal is to endow the mobile robot with visual perception capabilities so that it can interact with the users. We present the key modules of independent motion detection, object detection, body localization, person tracking, head pose estimation and action recognition and we explain how they serve the goal of natural integration of robots in social environments.
Some of the efficient, real-time vision-based functionalities of Hobbit are listed below:



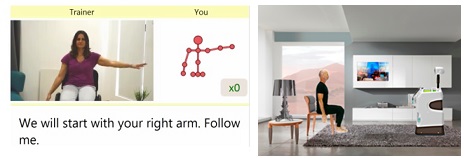
This work has been supported by the EU project Hobbit, FP7-288146 (STREP).
M. Foukarakis, I. Adami, D. Ioannidi, A. Leonidis, D. Michel, A. Qammaz,
K. Papoutsakis, M. Antona and A.A. Argyros, "A Robot-based Application for Physical Exercise Training", In International Conference on Information and Communication Technologies for Ageing Well and e-Health (ICT4AWE 2016), Scitepress, pp. 45-52, Rome, Italy, April 2016
BibTex,
PDF
D. Michel, K. Papoutsakis and A.A. Argyros, "Gesture Recognition Apparatuses, Methods and Systems for Human-Machine Interaction", United States Patent No 20160078289, Filed: 16 September, 2015, Published: 17 March, 2016
BibTex,
PDF,
DOI
D. Fischinger, P. Einramhof,
K. Papoutsakis, W. Wohlkinger, P. Mayer, P. Panek, S. Hofmann, T. Koertner, A. Weiss, A.A. Argyros and others, "Hobbit, a care robot supporting independent living at home: First prototype and lessons learned", Robotics and Autonomous Systems, Elsevier, vol. 75, no. A, pp. 60-78, January 2016
BibTex,
PDF,
DOI
D. Michel, K.E. Papoutsakis and A.A. Argyros, "Gesture Recognition Supporting the Interaction of Humans with Socially Assistive Robots", In Advances in Visual Computing (ISVC 2014), Springer, pp. 793-804, Las Vegas, Nevada, USA, December 2014.
BibTex,
PDF,
DOI
K. Papoutsakis, P. Padeleris, A. Ntelidakis, S. Stefanou, X. Zabulis, D. Kosmopoulos and A.A. Argyros, "Developing visual competencies for socially assistive robots: the HOBBIT approach", In International Conference on Pervasive Technologies Related to Assistive Environments (PETRA 2013), ACM, pp. 1-7, Rhodes, Greece, May 2013
BibTex,
PDF,
DOI
The electronic versions of the above publications can be downloaded from the publications page.
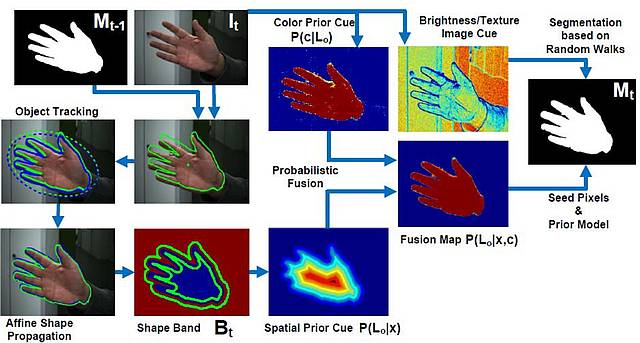
To achieve an efficient solution for simultaneous objecte tracking and fine segmentation, we tightly couple an existing kernel-based object tracking method with Random Walker-based image segmentation. Bayesian inference mediates between tracking and segmentation, enabling effective data fusion of pixel-wise spatial and color visual cues. The fine segmentation of an object at a certain frame provides tracking with reliable initialization for the next frame, closing the loop between the two building blocks of the proposed framework. The effectiveness of the proposed methodology is evaluated experimentally by comparing it to a large collection of state of the art tracking and video-based object segmentation methods on the basis of a data set consisting of several challenging image sequences for which ground truth data is available.
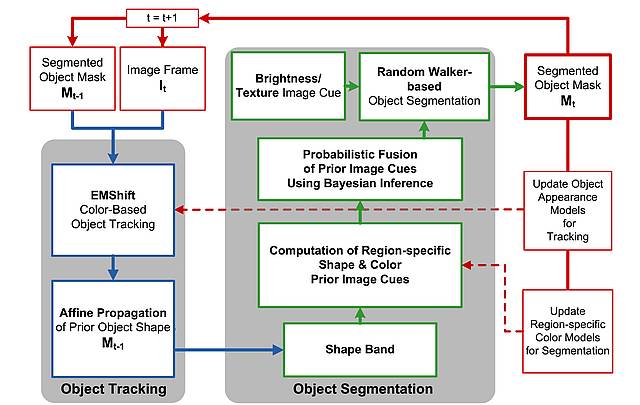
K. Papoutsakis, A.A. Argyros, “Integrating tracking with fine object segmentation”,
Image and Vision Computing, Volume 31, Issue 10, pp. 771-785, Oct. 2013.
BibTex,
PDF
K. Papoutsakis, A.A. Argyros, “Object tracking and segmentation in a closed loop”,
in Proceedings of the International Symposium on Visual Computing, ISVC’2010,
Las Vegas, USA, Advances in Visual Computing, Lecture Notes in Computer Science.
BibTex,
PDF,
DOI
The electronic versions of the above publications can be downloaded from the publications page.
This is a list of publications in scientific conferences and journals. You my also check my Google scholar profile.
We propose a novel unsupervised method that assesses the similarity of two videos on the basis of the estimated relatedness of the objects and their behavior, and provides arguments supporting this assessment. A video is represented as a complete undirected action graph that encapsulates information on the types of objects and the way they (inter) act. The similarity of a pair of videos is estimated based on the bipartite Graph Edit Distance (GED) of the corresponding action graphs. As a consequence, on-top of estimating a quantitative measure of video similarity, our method establishes spatiotemporal correspondences between objects across videos if these objects are semantically related, if/when they interact similarly, or both. We consider this an important step towards explainable assessment of video and action similarity. The proposed method is evaluated on a publicly available dataset on the tasks of activity classification and ranking and is shown to compare favorably to state of the art supervised learning methods.
We present a novel solution to the problem of detecting common actions in time series of motion capture data and videos. Given two action sequences, our method discovers all pairs of similar subsequences, i.e. subsequences that represent the same action. This is achieved in a completely unsupervised manner, i.e., without any prior knowledge of the type of actions, their number and their duration. These common subsequences (commonalities) may be located anywhere in the original sequences, may differ in duration and may be performed under different conditions e.g., by a different actor.
The Bags of Visua lWords (BoVWs) framework has been applied successfully to several computer vision tasks. In this work we are particularly interested on its application to the problem of action recognition/classification. The key design decisions for a method that follows the BoVWs framework are (a) the visual features to be employed, (b) the size of the codebook to be used for representing a certain action and (c) the classifier applied to the developed representation to solve the classification task. We perform several experiments to investigate a variety of options regarding all the aforementioned design parameters. We also propose a new feature type and we suggest a method that determines automatically the size of the codebook. The experimental results show that our proposals produce results that are competitive to the outcomes of state of the art methods.
Given two action sequences, we are interested in spotting/co-segmenting all pairs of sub-sequences that represent the same action. We propose a totally unsupervised solution to this problem. No a-priori model of the actions is assumed to be available. The number of common subsequences may be unknown. The sub-sequences can be located anywhere in the original sequences, may differ in duration and the corresponding actions may be performed by a different person, in different style. We treat this type of temporal action co-segmentation as a stochastic optimization problem that is solved by employing Particle Swarm Optimization (PSO). The objective function that is minimized by PSO capitalizes on Dynamic TimeWarping (DTW) to compare two action sequences. Due to the generic problem formulation and solution, the proposed method can be applied to motion capture (i.e., 3D skeletal) data or to conventional RGB video data acquired in the wild. We present extensive quantitative experiments on several standard, ground truthed datasets. The obtained results demonstrate that the proposed method achieves a remarkable increase in co-segmentation quality compared to all tested existing state of the art methods.
In this work, we propose a discriminative framework for online simultaneous segmentation and classification of modeled visual actions that can be performed in the context of other, unknown actions. To this end, we employ Hough transform to vote in a 3D space for the begin point, the end point and the label of the segmented part of the input stream. An SVM is used to model each class and to suggest putative labeled segments on the timeline. To identify the most plausible segments among the putative ones we apply a dynamic programming algorithm, which maximises the likelihood for label assignment in linear time. The performance of our method is evaluated on synthetic, as well as on real data (Weizmann, TUM Kitchen, UTKAD and Berkeley multimodal human action databases). Extensive quantitative results obtained on a number of standard datasets demonstrate that the proposed approach is of comparable accuracy to the state of the art for online stream segmentation and classification when all performed actions are known and performs considerably better in the presence of unmodeled actions.
According to studies, performing physical exercise is beneficial for reducing the risk of falling in the elderly and prolonging their stay at home. In addition, regular exercising helps cognitive function and increases positive behaviour for seniors with cognitive impairment and dementia. In this paper, a fitness application integrated into a service robot is presented. Its aim is to motivate the users to perform physical training by providing relevant exercises and useful feedback on their progress. The application utilizes the robot vision system to track and recognize user movements and activities and supports multimodal interaction with the user. The pa-per describes the design challenges, the system architecture, the user interface and the human motion capturing module. Additionally, it discusses some results from user testing in laboratory and home-based trials.
The GESTURE RECOGNITION APPARATUSES, METHODS AND SYSTEMS FOR HUMAN-MACHINE INTERACTION (GRA) discloses vision-based gesture recognition. GRA can be implemented in any application involving tracking, detection and/or recognition of gestures or motion in general. Disclosed methods and systems consider a gestural vocabulary of a predefined number of user specified static and/or dynamic hand gestures that are mapped with a database to convey messages. In one implementation, the disclosed systems and methods support gesture recognition by detecting and tracking body parts, such as arms, hands and fingers, and by performing spatio-temporal segmentation and recognition of the set of predefined gestures, based on data acquired by an RGBD sensor. In one implementation, a model of the hand is employed to detect hand and finger candidates. At a higher level, hand posture models are defined and serve as building blocks to recognize gestures.
One option to address the challenge of demographic transition is to build robots that enable aging in place. Falling has been identified as the most relevant factor to cause a move to a care facility. The Hobbit project combines research from robotics, gerontology, and human–robot interaction to develop a care robot which is capable of fall prevention and detection as well as emergency detection and handling. Moreover, to enable daily interaction with the robot, other functions are added, such as bringing objects, offering reminders, and entertainment. The interaction with the user is based on a multimodal user interface including automatic speech recognition, text-to-speech, gesture recognition, and a graphical touch-based user interface. We performed controlled laboratory user studies with a total of 49 participants (aged 70 plus) in three EU countries (Austria, Greece, and Sweden). The collected user responses on perceived usability, acceptance, and affordability of the robot demonstrate a positive reception of the robot from its target user group. This article describes the principles and system components for navigation and manipulation in domestic environments, the interaction paradigm and its implementation in a multimodal user interface, the core robot tasks, as well as the results from the user studies, which are also reflected in terms of lessons we learned and we believe are useful to fellow researchers.
We propose a new approach for vision-based gesture recognition to support robust and efficient human robot interaction towards developing socially assistive robots. The considered gestural vocabulary consists of five, user specified hand gestures that convey messages of fundamental importance in the context of human-robot dialogue. Despite their small number, the recognition of these gestures exhibits considerable challenges. Aiming at natural, easy-to-memorize means of interaction, users have identified gestures consisting of both static and dynamic hand configurations that involve different scales of observation (from arms to fingers) and exhibit intrinsic ambiguities. Moreover, the gestures need to be recognized regardless of the multifaceted variability of the human subjects performing them. Recognition needs to be performed online, in continuous video streams containing other irrelevant/unmodeled motions. All the above need to be achieved by analyzing information acquired by a possibly moving RGBD camera, in cluttered environments with considerable light variations. We present a gesture recognition method that addresses the above challenges, as well as promising experimental results obtained from relevant user trials.
In this work, we provide a discriminative framework for online simultaneous segmentation and classification of visual actions, which deals effectively with unknown sequences that may interrupt the known sequential patterns. To this end we employ Hough transform to vote in a 3D space for the begin point, the end point and the label of the segmented part of the input stream. An SVM is used to model each class and to suggest putative labeled segments on the timeline. To identify the most plausible segments among the putative ones we apply a dynamic programming algorithm, which maximises an objective function for label assignment in linear time. The performance of our method is evaluated on synthetic as well as on real data (Weizmann and Berkeley multimodal human action database). The proposed approach is of comparable accuracy to the state of the art for online stream segmentation and classification and performs considerably better in the presence of previously unseen actions.
We present a novel method for on-line, joint object tracking and segmentation in a monocular video captured by a possibly moving camera. Our goal is to integrate tracking and fine segmentation of a single, previously unseen, potentially non-rigid object of unconstrained appearance, given its segmentation in the first frame of an image sequence as the only prior information. To this end, we tightly couple an existing kernel-based object tracking method with Random Walker-based image segmentation. Bayesian inference mediates between tracking and segmentation, enabling effective data fusion of pixel-wise spatial and color visual cues. The fine segmentation of an object at a certain frame provides tracking with reliable initialization for the next frame, closing the loop between the two building blocks of the proposed framework. The effectiveness of the proposed methodology is evaluated experimentally by comparing it to a large collection of state of the art tracking and video-based object segmentation methods on the basis of a data set consisting of several challenging image sequences for which ground truth data is available.
One option to face the aging society is to build robots that help old persons to stay longer at home. We present Hobbit, a robot that attempts to let users feel safe at home by preventing and detecting falls. Falling has been identified as the highest risk for older adults of getting injured so badly that they can no longer live independently at home and have to move to a care facility. Hobbit is intended to provide high usability and acceptability for the target user group while, at the same time, needs to be affordable for private customers. The development process so far (1.5 years) included a thorough user requirement analysis, conceptual interaction design, prototyping and implementation of key behaviors, as well as extensive empirical testing with target users in the laboratory. We shortly describe the overall interdisciplinary decision-making and conceptualization of the robot and will then focus on the system itself describing the hardware, basic components, and the robot tasks. Finally, we will summarize the findings of the first empirical test with 49 users in three countries and give an outlook of how the platform will be extended in future.
In this paper, we present our approach towards developing visual competencies for socially assistive robots within the framework of the HOBBIT project. We show how we integrated several vision modules using a layered architectural scheme. Our goal is to endow the mobile robot with visual perception capabilities so that it can interact with the users. We present the key modules of independent motion detection, object detection, body localization, person tracking, head pose estimation and action recognition and we explain how they serve the goal of natural integration of robots in social environments.
We introduce a new method for integrated tracking and segmentation of a single non-rigid object in an monocular video, captured by a possibly moving camera. A closed-loop interaction between EM-like color-histogram-based tracking and Random Walker-based image segmentation is proposed, which results in reduced tracking drifts and in fine object segmentation. More specifically, pixel-wise spatial and color image cues are fused using Bayesian inference to guide object segmentation. The spatial properties and the appearance of the segmented objects are exploited to initialize the tracking algorithm in the next step, closing the loop between tracking and segmentation. As confirmed by experimental results on a variety of image sequences, the proposed approach efficiently tracks and segments previously unseen objects of varying appearance and shape, under challenging environmental conditions.
I have been serving as a teaching assistant during my post-graduate studies in the Computer Science Department, University of Crete, for the following courses: